> ## Documentation Index
> Fetch the complete documentation index at: https://docs.zenrows.com/llms.txt
> Use this file to discover all available pages before exploring further.
# Capture Network Requests (XHR/Fetch)
> Intercept XHR and Fetch API network requests to extract structured JSON data from JavaScript-heavy dynamic websites using ZenRows.
Many modern websites load data dynamically through background API calls rather than including everything in the initial HTML. These XHR (XMLHttpRequest) and Fetch requests often contain the exact data you need in a clean JSON format, making them more reliable than scraping HTML elements.
This guide shows you how to identify and capture these network requests using two ZenRows approaches: the Universal Scraper API for simple integration, and the Scraping Browser for advanced control.
While ZenRows can capture XHR/Fetch requests during page rendering, this feature is designed as a supplementary capability rather than our core offering. ZenRows specializes in HTML content extraction and JavaScript rendering for traditional web scraping scenarios.
This guide demonstrates the capability for educational purposes and specific use cases where understanding background API calls enhances your web scraping strategy.
## Who is this for?
This guide is for developers who need to extract data from websites that load content dynamically through JavaScript and API calls, such as infinite scroll pages, search results, or real-time data feeds.
## What you'll learn
* Identify XHR/Fetch requests using browser developer tools
* Capture network requests with the Universal Scraper API
* Use the Scraping Browser to intercept and analyze API calls
## Understanding Network Requests
The first step is understanding which network requests load the data you need. We'll use Chrome's Developer Tools to monitor network activity and identify the relevant API calls.
Let's use a practical example with a "Load More" page:
1. Navigate to [https://www.scrapingcourse.com/button-click](https://www.scrapingcourse.com/button-click)
2. Right-click anywhere on the page and select **Inspect**
3. Go to **Network** → **Fetch/XHR**
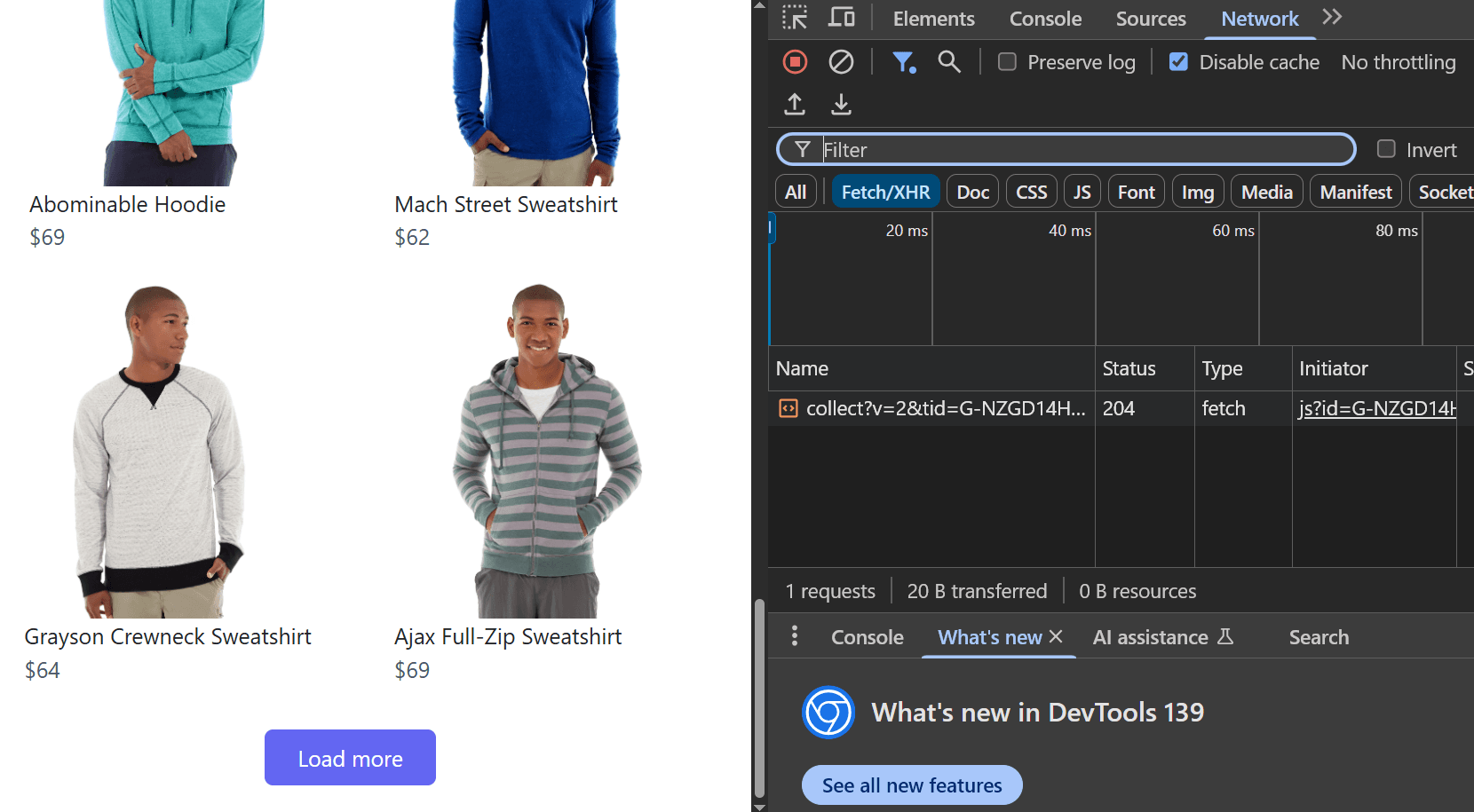 1. Click the **Load More** button on the site to trigger a data-loading event
2. Observe the changes in the Fetch/XHR calls
3. Each click calls a `products?offset` API as shown in the image below
4. Click one of the offset requests to view the API endpoint that was called
1. Click the **Load More** button on the site to trigger a data-loading event
2. Observe the changes in the Fetch/XHR calls
3. Each click calls a `products?offset` API as shown in the image below
4. Click one of the offset requests to view the API endpoint that was called
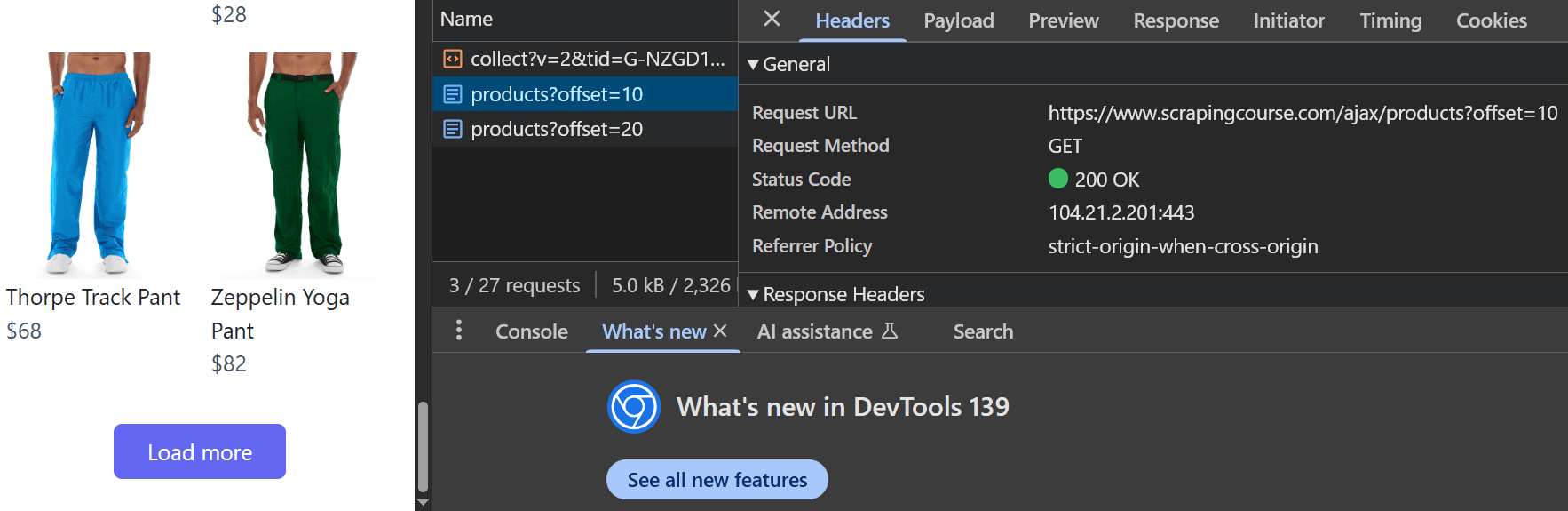 The network inspection shows that the requested API endpoint is: `https://www.scrapingcourse.com/ajax/products?offset=10`
Opening this URL directly in your browser returns the raw data without visual design:
The network inspection shows that the requested API endpoint is: `https://www.scrapingcourse.com/ajax/products?offset=10`
Opening this URL directly in your browser returns the raw data without visual design:
 The `offset` query parameter determines which set of data is loaded. For example:
* `offset=0` loads the initial data visible in the viewport
* `offset=10` loads the next set of products
* `offset=50` loads data for the sixth scroll position
Network request behavior can vary significantly between websites. Some endpoints may return HTML pages, while others provide JSON or different data formats. Always inspect the specific network responses of your target site to determine the appropriate handling method.
## Method 1: Universal Scraper API
The Universal Scraper API provides the simplest way to capture network requests. Use the `json_response` parameter to automatically capture all XHR/Fetch requests made during page rendering, combined with `js_instructions` to trigger the necessary interactions.
```python Python theme={null}
# pip install requests
import requests
url = 'https://www.scrapingcourse.com/button-click'
apikey = 'YOUR_ZENROWS_API_KEY'
params = {
'url': url,
'apikey': apikey,
'js_render': 'true',
'json_response': 'true', # Capture network requests made during page render
'js_instructions': """[
{"wait_for":"#load-more-btn"},
{"click":"#load-more-btn"},
{"wait":1000}
]""",
'premium_proxy': 'true',
}
response = requests.get('https://api.zenrows.com/v1/', params=params)
print(response.text)
```
You can find more information about the JavaScript Instructions parameter in the [JavaScript Instructions](/universal-scraper-api/features/js-instructions) and JSON Response parameters in the [JSON Response](/universal-scraper-api/features/json-response) documentation pages.
Response example:
```json JSON Response theme={null}
{
"html": "
The `offset` query parameter determines which set of data is loaded. For example:
* `offset=0` loads the initial data visible in the viewport
* `offset=10` loads the next set of products
* `offset=50` loads data for the sixth scroll position
Network request behavior can vary significantly between websites. Some endpoints may return HTML pages, while others provide JSON or different data formats. Always inspect the specific network responses of your target site to determine the appropriate handling method.
## Method 1: Universal Scraper API
The Universal Scraper API provides the simplest way to capture network requests. Use the `json_response` parameter to automatically capture all XHR/Fetch requests made during page rendering, combined with `js_instructions` to trigger the necessary interactions.
```python Python theme={null}
# pip install requests
import requests
url = 'https://www.scrapingcourse.com/button-click'
apikey = 'YOUR_ZENROWS_API_KEY'
params = {
'url': url,
'apikey': apikey,
'js_render': 'true',
'json_response': 'true', # Capture network requests made during page render
'js_instructions': """[
{"wait_for":"#load-more-btn"},
{"click":"#load-more-btn"},
{"wait":1000}
]""",
'premium_proxy': 'true',
}
response = requests.get('https://api.zenrows.com/v1/', params=params)
print(response.text)
```
You can find more information about the JavaScript Instructions parameter in the [JavaScript Instructions](/universal-scraper-api/features/js-instructions) and JSON Response parameters in the [JSON Response](/universal-scraper-api/features/json-response) documentation pages.
Response example:
```json JSON Response theme={null}
{
"html": "..... HTML content .....
",
"xhr": [
... other XHR requests ...
{
"url": "https://www.scrapingcourse.com/ajax/products?offset=10",
"body": "...
...