Who is this for?
This guide is for developers who need to extract data from websites that load content dynamically through JavaScript and API calls, such as infinite scroll pages, search results, or real-time data feeds.What you’ll learn
- Identify XHR/Fetch requests using browser developer tools
- Capture network requests with the Universal Scraper API
- Use the Scraping Browser to intercept and analyze API calls
Understanding Network Requests
The first step is understanding which network requests load the data you need. We’ll use Chrome’s Developer Tools to monitor network activity and identify the relevant API calls. Let’s use a practical example with a “Load More” page:1
Open Developer Tools
- Navigate to https://www.scrapingcourse.com/button-click
- Right-click anywhere on the page and select Inspect
- Go to Network → Fetch/XHR
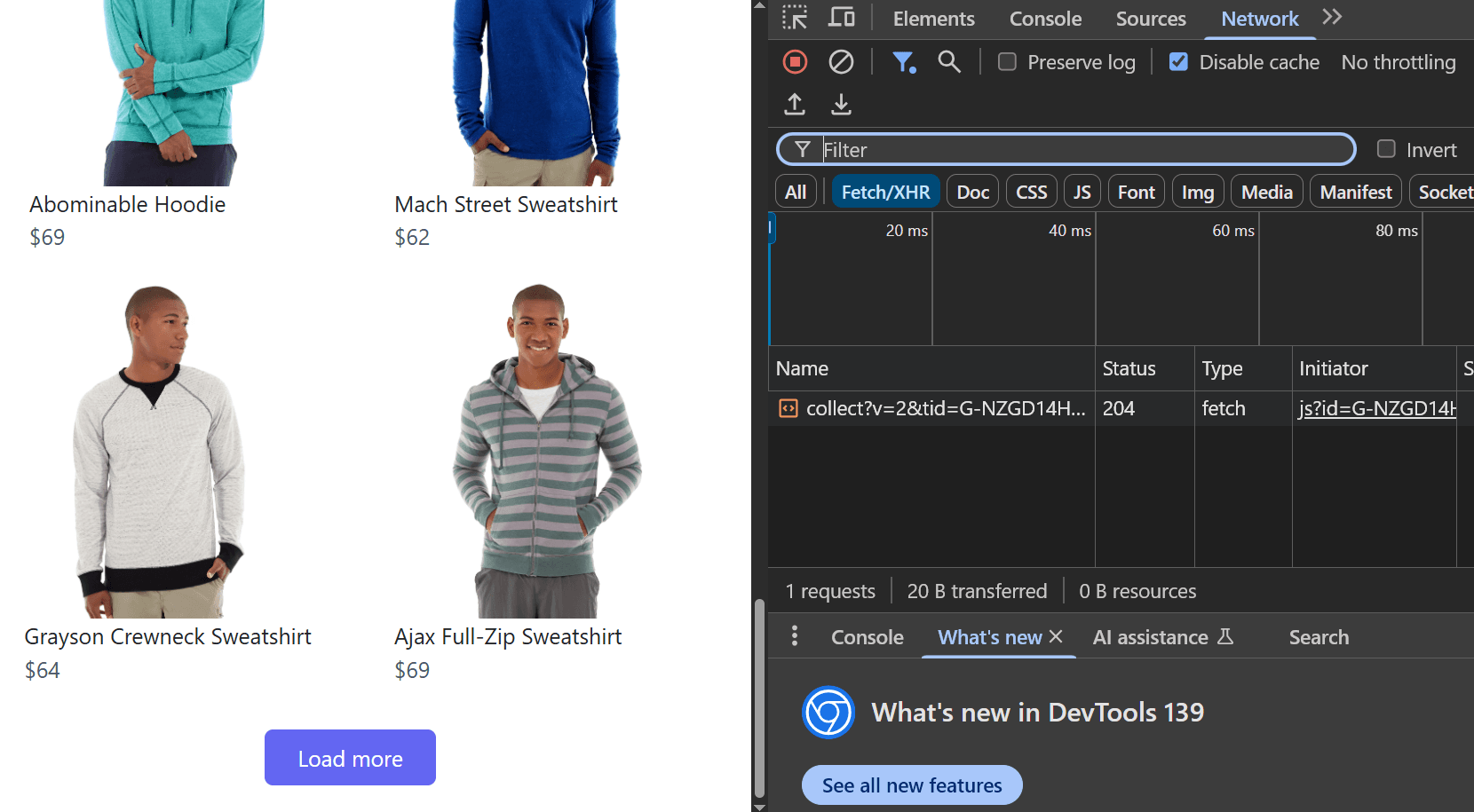
2
Trigger Network Activity
- Click the Load More button on the site to trigger a data-loading event
- Observe the changes in the Fetch/XHR calls
- Each click calls a
products?offsetAPI as shown in the image below - Click one of the offset requests to view the API endpoint that was called
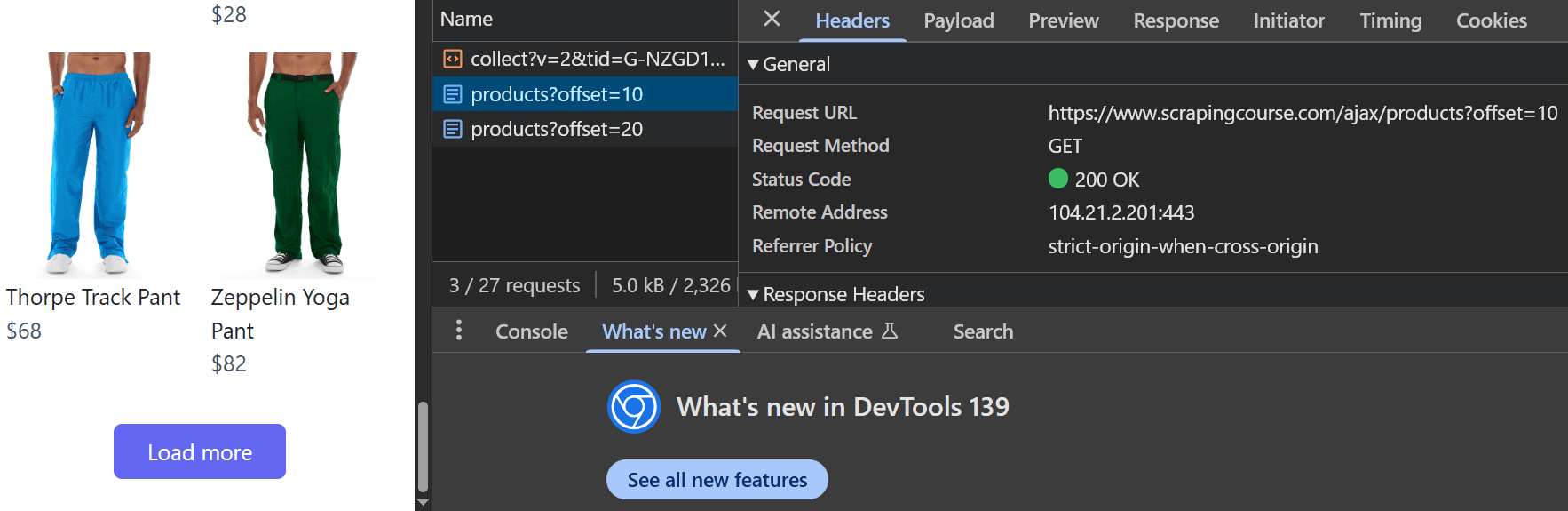
3
Analyze the API Endpoint
The network inspection shows that the requested API endpoint is:  The
The
https://www.scrapingcourse.com/ajax/products?offset=10Opening this URL directly in your browser returns the raw data without visual design:offset query parameter determines which set of data is loaded. For example:offset=0loads the initial data visible in the viewportoffset=10loads the next set of productsoffset=50loads data for the sixth scroll position
Network request behavior can vary significantly between websites. Some endpoints may return HTML pages, while others provide JSON or different data formats. Always inspect the specific network responses of your target site to determine the appropriate handling method.
Method 1: Universal Scraper API
The Universal Scraper API provides the simplest way to capture network requests. Use thejson_response parameter to automatically capture all XHR/Fetch requests made during page rendering, combined with js_instructions to trigger the necessary interactions.
Python
You can find more information about the JavaScript Instructions parameter in the JavaScript Instructions and JSON Response parameters in the JSON Response documentation pages.
JSON Response
Method 2: Scraping Browser
The Scraping Browser provides more control over network request capture and allows you to process requests in real-time as they occur. It is recommended to use the Scraping Browser for more complex scraping tasks or when the Universal Scraper API is not enough.Best Practices
Request Filtering:- Filter by URL patterns to capture only relevant API calls
- Use resource type filtering to focus on XHR/Fetch requests
- Monitor specific endpoints that contain the data you need
- Set appropriate
waittimes to ensure all requests complete - Use targeted selectors in
wait_forinstructions - Limit capture duration to avoid unnecessary data collection
- Parse JSON responses when possible for structured data
- Handle different response formats (JSON, XML, HTML)
- Store request metadata (headers, status codes) for debugging
- Implement retry logic for failed network captures
- Validate captured data before processing
- Log network errors for troubleshooting
Troubleshooting
No XHR requests captured:- Ensure
js_renderis enabled - Increase
waittimes to allow requests to complete - Check if the target element exists and is clickable
- Verify that JavaScript is required to load the content
- Use
custom_headersparameter with the Universal Scraper API - Set headers before navigation with the Scraping Browser
- Check if the site requires cookies or session tokens
- Increase the
waitparameter to allow all requests to finish - Use
wait_forwith specific selectors instead of fixed timeouts - Monitor the network tab to understand the request timing
- Adjust URL pattern matching for your specific target site
- Check the
resource_typeof requests you want to capture - Use broader filters initially, then narrow down based on results