- Extract specific data points like product prices, titles, or links
- Transform unstructured HTML into structured JSON for easy processing
- Reduce response size by getting only relevant information
- Automate data collection from consistent page structures
- Build data pipelines that require predictable JSON output
The CSS Extractor works with both standard scraping and JavaScript rendering. For dynamic content that loads via AJAX, combine it with
js_render=true for complete data extraction.How CSS Extractor works
CSS Extractor processes the rendered HTML content using CSS selectors or XPath expressions to identify and extract specific elements. The browser parses the page content, locates elements matching your selectors, and returns the extracted data in a structured JSON format. This process captures:- Text content from matching elements
- Attribute values (href, src, data attributes, etc.)
- Multiple elements as arrays when selectors match several items
- Complex data structures using nested extraction rules
Basic usage
Enable CSS Extractor by adding thecss_extractor parameter with a JSON object defining your extraction rules:
Extraction patterns
The CSS Extractor supports various extraction patterns to handle different types of content and data structures.Basic text extraction
Extract text content from elements using standard CSS selectors:Attribute extraction
Extract specific attributes from elements by adding@attribute_name to your selector:
Multiple elements
When your selector matches multiple elements, CSS Extractor automatically returns an array:Advanced selectors
Use complex CSS selectors for precise targeting:XPath expressions
For more complex extractions, use XPath expressions. XPath is a query language for selecting nodes in XML/HTML documents, offering more flexibility than CSS selectors:Complex extraction example
Here’s a comprehensive example showing how to extract structured product data from an e-commerce page:JSON
When to use CSS Extractor
CSS Extractor is essential for these scenarios: E-commerce data collection- Product information - Extract prices, titles, descriptions, and availability
- Inventory monitoring - Track stock levels and price changes
- Competitor analysis - Collect product data from multiple sources
- Review aggregation - Extract customer reviews and ratings
- Category browsing - Collect product listings from category pages
- News articles - Extract headlines, authors, publication dates, and content
- Blog posts - Collect titles, excerpts, and metadata
- Job listings - Collect job titles, companies, locations, and requirements
- Real estate - Extract property details, prices, and contact information
- Price tracking - Monitor price changes across multiple retailers
- Content changes - Track updates to specific page elements
- SEO analysis - Extract meta tags, headings, and structured data
- Form data - Collect form fields and validation tokens
- API endpoint discovery - Extract AJAX endpoints and data sources
- Quality assurance - Verify that specific elements appear correctly
- A/B testing - Extract different page variants for comparison
- Performance monitoring - Track loading of specific page components
- Integration testing - Verify data consistency across different pages
For pages with dynamic content that loads via JavaScript, combine CSS Extractor with
js_render=true to ensure all content is captured before extraction.Best practices
Combine with appropriate ZenRows parameters
Maximize your extraction success by strategically combining CSS Extractor with other ZenRows features. While CSS Extractor works independently with static content, pairing it with complementary parameters ensures reliable data extraction across different website types and protection levels.For dynamic content that loads via JavaScript
When targeting websites that render content dynamically, enable JavaScript rendering and use timing controls to ensure all elements are present before extraction:Python
For protected or geo-restricted websites
Combine with proxy features to access content that may be blocked or restricted by location:Python
For complex interactive websites
Use JavaScript Instructions to simulate user interactions before extracting data:Python
Choose stable and reliable selectors
The foundation of successful CSS extraction is using selectors that remain consistent over time. Prioritize semantic and stable attributes over auto-generated or fragile ones:Python
data-*attributes (e.g.,[data-testid="product"])- Semantic IDs (e.g.,
#product-title) - Semantic class names (e.g.,
.product-description) - Element types with attributes (e.g.,
img[alt="product"]) - Complex descendant selectors (use sparingly)
Test selectors before implementation
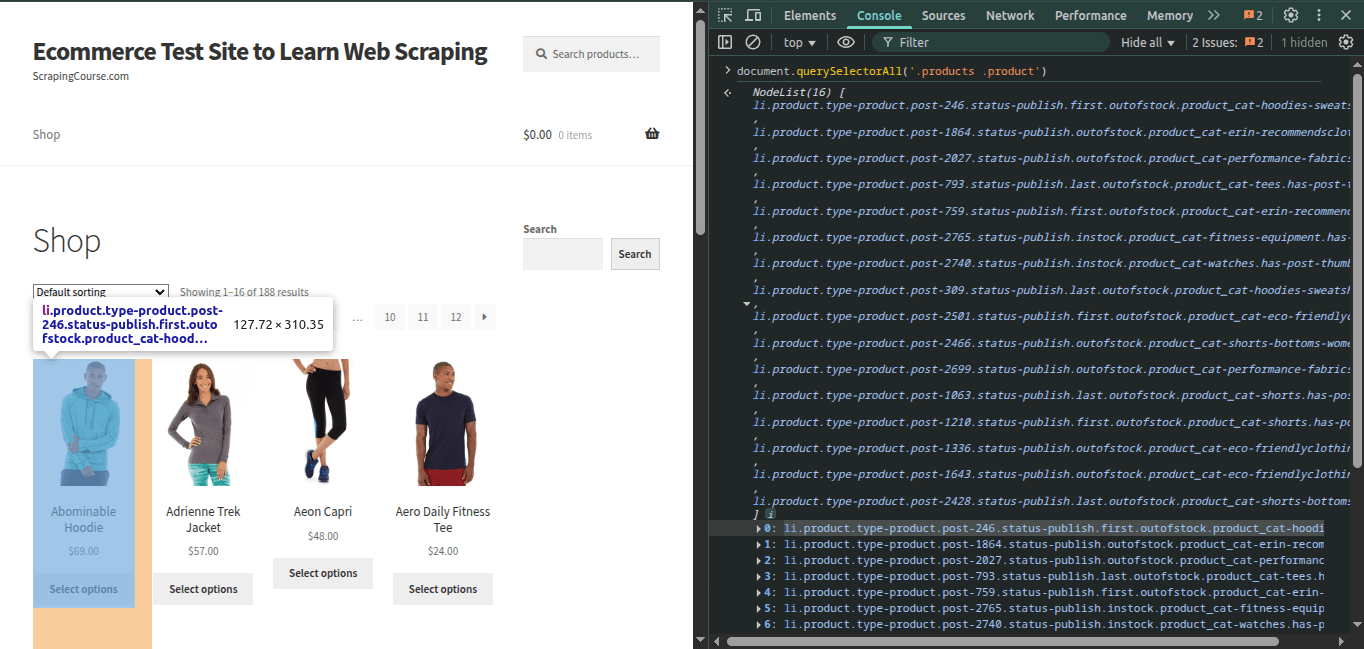
Always verify your CSS selectors work correctly on the target website before deploying them in production. This prevents extraction failures and ensures reliable data collection.1
Open the target website
Navigate to the page you want to scrape in your browser
2
Access DevTools console
- Right-click on the page and select “Inspect” or press F12
- Navigate to the “Console” tab
- Test your selector using JavaScript:
3
Validate results
- Ensure the selector returns the expected number of elements
- Verify the content matches what you want to extract
- Test attribute extraction (href, src, data attributes)
Troubleshooting
Common issues and solutions
Handling selector failures
If ZenRows cannot find matching elements for your CSS selectors, it will retry internally several times. If selectors still don’t match after the timeout period, you may receive incomplete data or empty results. This typically means your selectors don’t exist in the final HTML or are too fragile to be reliable.Selector not present in final HTML
1
Inspect the site using browser DevTools
- Open the target page in your browser
- Right-click the target content and choose “Inspect”
- Check if your selector exists after the page fully loads
2
Verify your selector
- Run
document.querySelectorAll('your_selector')in the browser console - If it returns no elements, your selector is incorrect
3
Optimization tips
- Use simple selectors like
.classor#id - Prefer stable attributes like
[data-testid="item"] - Avoid overly specific or deep descendant selectors
Dynamic or fragile selectors
Some websites use auto-generated class names that change frequently. These are considered dynamic and unreliable for consistent data extraction.- Re-check the page in DevTools if a previously working selector fails
- Look for stable attributes like
data-*attributes - Use attribute-based selectors, which are more stable over time
Python
Python
Content is conditional or missing
When scraping at scale, it’s common to encounter pages where expected content is missing or appears under certain conditions. Common scenarios where selectors might fail:- Inexistent elements - The product exists, but elements like price or “Add to cart” button are missing
- Deleted or unavailable pages - Product URLs may be valid, but the product has been removed
- Failed page loads - The page might fail to load properly, causing selectors to miss content
- Conditional rendering - Content only renders based on user location, browser behavior, or interactions
-
Monitor original status codes
PythonFor more details check the original_status documentation
-
Allow error status codes
PythonFor more details check the allowed_status_codes documentation
-
Best practices for handling missing content
- Anticipate that some selectors may not match if content is missing
- Include fallback selectors for critical data points
- Check for error indicators in your extraction rules
- Monitor extraction success rates to detect site changes
Selector exists but extraction still fails
Sometimes your CSS selector is correct but still doesn’t extract the expected data: Common causes and solutions:-
Element is hidden (
display: none) - CSS Extractor can still extract hidden content. If you need visible elements only, target child elements or wrappers that appear when content is shown.You can find more information about advanced CSS selectors here. -
Content appears after user interaction - Use
js_instructionsto simulate clicks or scrolls before extraction:Python -
Page relies on slow external scripts - Try waiting for different selectors that appear earlier, or increase wait times
Python
Pricing
Thecss_extractor parameter is included at no additional cost with all ZenRows requests - you only pay extra for JavaScript Render and Premium Proxy when used.
Frequently Asked Questions (FAQ)
Can I use CSS Extractor without JavaScript rendering?
Can I use CSS Extractor without JavaScript rendering?
Yes, CSS Extractor works with both standard scraping and JavaScript rendering. Use
js_render=true only when you need to extract content that loads dynamically via JavaScript.What's the difference between CSS selectors and XPath?
What's the difference between CSS selectors and XPath?
CSS selectors are simpler and more familiar to web developers, while XPath offers more powerful querying capabilities. CSS selectors are sufficient for most use cases, but XPath is useful for complex document traversal and text manipulation.
How many extraction rules can I include in one request?
How many extraction rules can I include in one request?
There’s no strict limit on the number of extraction rules, but keep in mind that more complex extractions may increase processing time and response size. Focus on extracting only the data you actually need.
Can I extract nested or hierarchical data structures?
Can I extract nested or hierarchical data structures?
CSS Extractor returns flat JSON structures. For complex nested data, you may need to make multiple requests or use different selectors to extract related data points separately.
What happens if my selector matches no elements?
What happens if my selector matches no elements?
If a selector doesn’t match any elements, that field will be null or omitted from the JSON response. This won’t cause an error, but you should validate your results to ensure critical data was extracted.
Can I combine CSS Extractor with other ZenRows features?
Can I combine CSS Extractor with other ZenRows features?
Yes, CSS Extractor works seamlessly with all ZenRows features including Premium Proxy, JavaScript rendering, Screenshots, and Block Resources. This allows you to handle complex scraping scenarios while getting structured data output.
How do I extract data from elements that appear after user interactions?
How do I extract data from elements that appear after user interactions?
Use JavaScript Instructions to simulate user interactions (clicks, scrolls, form submissions) before extraction. The CSS Extractor will then process the updated page content after these interactions complete.
Is there a way to extract only the first match when multiple elements exist?
Is there a way to extract only the first match when multiple elements exist?
CSS Extractor automatically returns arrays for multiple matches. To get only the first match, you can either make your selector more specific or process the results in your code to take only the first item from arrays.