Documentation Index
Fetch the complete documentation index at: https://docs.zenrows.com/llms.txt
Use this file to discover all available pages before exploring further.
Switching from the Universal Scraper API to the dedicated Amazon Scraper APIs streamlines extraction and minimizes development effort.
This guide provides a step-by-step migration process:
- First, we present an end-to-end script using the Universal Scraper API.
- Then, we demonstrate how to transition to the dedicated Scraper APIs for improved accuracy and ease of use.
Follow this guide to implement the new API in just a few steps.
Initial Method via the Universal Scraper API
Using the Universal Scraper API, you’d typically extract product URLs from a product listing, visit each page via the URL, and save individual product data into a CSV file:
# pip install requests
import requests
STARTING_URL = "https://www.amazon.com/s?k=keyboard"
def get_html(url):
apikey = "YOUR_ZENROWS_API_KEY"
params = {
"url": url,
"apikey": apikey,
"js_render": "true",
"premium_proxy": "true",
}
response = requests.get("https://api.zenrows.com/v1/", params=params)
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser")
else:
print(
f"Request failed with status code {response.status_code}: {response.text}"
)
return None
Parsing Logic and Extracting Product Data
Once the HTML content is obtained, the next step is to parse the webpage and extract the product information you need: title, price, link, and availability.
from bs4 import BeautifulSoup
def extract_product_links():
soup = get_html(STARTING_URL)
products = []
if not soup:
return products
for item in soup.find_all("div", class_="s-result-item"):
title_elem = item.find("a", class_="s-link-style")
link_elem = item.find("a", class_="s-link-style")
price_elem = item.find("span", class_="a-offscreen")
title = title_elem.get_text(strip=True) if title_elem else "N/A"
product_url = (
f"https://www.amazon.com{link_elem['href']}" if link_elem else "N/A"
)
price = price_elem.get_text(strip=True) if price_elem else "N/A"
products.append(
{
"title": title,
"url": product_url,
"price": price,
"availability": "Unknown",
}
)
return products
def get_availability(product_url):
soup = get_html(product_url)
if soup:
availability_elem = soup.find(id="availability")
return (
availability_elem.get_text(strip=True)
if availability_elem
else "Unavailable"
)
return "Unavailable"
def update_availability(products):
for product in products:
if product["url"] != "N/A":
product["availability"] = get_availability(product["url"])
return products
Store the data in a CSV file
Once all data is collected and structured, the following function saves the data into a CSV file:
import csv
def save_to_csv(data, filename="amazon_products.csv"):
with open(filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(
file, fieldnames=["title", "url", "price", "availability"]
)
writer.writeheader()
writer.writerows(data)
# save to CSV
data = extract_product_links()
data = update_availability(data)
save_to_csv(data)
print("Data saved to amazon_products.csv")
Here’s Everything Together
Here’s the complete Python script combining all the logic we explained above.
# pip install requests beautifulsoup4 csv
import requests
import csv
from bs4 import BeautifulSoup
STARTING_URL = "https://www.amazon.com/s?k=keyboard"
def get_html(url):
apikey = "YOUR_ZENROWS_API_KEY"
params = {
"url": url,
"apikey": apikey,
"js_render": "true",
"premium_proxy": "true",
}
response = requests.get("https://api.zenrows.com/v1/", params=params)
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser")
else:
print(
f"Request failed with status code {response.status_code}: {response.text}"
)
return None
def extract_product_links():
soup = get_html(STARTING_URL)
products = []
if not soup:
return products
for item in soup.find_all("div", class_="s-result-item"):
title_elem = item.find("a", class_="s-link-style")
link_elem = item.find("a", class_="s-link-style")
price_elem = item.find("span", class_="a-offscreen")
title = title_elem.get_text(strip=True) if title_elem else "N/A"
product_url = (
f"https://www.amazon.com{link_elem['href']}" if link_elem else "N/A"
)
price = price_elem.get_text(strip=True) if price_elem else "N/A"
products.append(
{
"title": title,
"url": product_url,
"price": price,
"availability": "Unknown",
}
)
return products
def get_availability(product_url):
soup = get_html(product_url)
if soup:
availability_elem = soup.find(id="availability")
return (
availability_elem.get_text(strip=True)
if availability_elem
else "Unavailable"
)
return "Unavailable"
def update_availability(products):
for product in products:
if product["url"] != "N/A":
product["availability"] = get_availability(product["url"])
return products
def save_to_csv(data, filename="amazon_products.csv"):
with open(filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(
file, fieldnames=["title", "url", "price", "availability"]
)
writer.writeheader()
writer.writerows(data)
# save to CSV
data = extract_product_links()
data = update_availability(data)
save_to_csv(data)
print("Data saved to amazon_products.csv")
Transition to the Amazon Scraper API
The Scraper API offers a more streamlined experience than the Universal Scraper API. It eliminates the parsing stage and instantly delivers ready-to-use data at your fingertips.
You can extract product data from Amazon using the following Scraper APIs:
- Amazon Product Discovery API: Retrieves a list of products based on a search term. Here’s the endpoint:
https://ecommerce.api.zenrows.com/v1/targets/amazon/discovery/<search_term>
To implement your Amazon scraper, simply provide your ZenRows API key as a request parameter and append your search term to the API endpoint.
- Product Information API: Fetches detailed information from individual product pages. See the endpoint below:
https://ecommerce.api.zenrows.com/v1/targets/amazon/products/<ASIN>
Some product details (e.g., Availability data) are only available on individual product pages and won’t be returned in a product listing. To retrieve this information, you can access each product page using the ASIN extracted from the Product Discovery endpoint.
To streamline this process, the Amazon Scraper APIs allow you to enhance the previous Universal Scraper API method with the following steps:
- Retrieve Amazon search results using the Product Discovery endpoint.
- Extract each product’s ASIN from the JSON response.
- Use the ASIN to fetch product details (e.g., Availability) from the Product Information endpoint.
- Update the initial search results with each product’s availability data obtained from the Product Information endpoint.
Here’s the updated code using the Amazon Scraper APIs:
# pip install requests
import requests
import csv
params = {
"apikey": "YOUR_ZENROWS_API_KEY",
}
# API Endpoints
discovery_endpoint = "https://ecommerce.api.zenrows.com/v1/targets/amazon/discovery/"
product_endpoint = "https://ecommerce.api.zenrows.com/v1/targets/amazon/products/"
# search Term
search_term = "keyboard"
# generic function to fetch data from the Scraper APIs
def scraper(endpoint, suffix):
url = f"{endpoint}{suffix}"
response = requests.get(url, params=params)
try:
return response.json()
except ValueError:
print(f"Failed to parse JSON from {url}")
return {}
def scrape_discovery(search_term):
return scraper(discovery_endpoint, search_term).get("products_list", [])
def scrape_product(asin):
return scraper(product_endpoint, asin)
# fetch product list
data = scrape_discovery(search_term)
# fetch product details for each item
for item in data:
asin = item.get("product_id")
if asin:
product_result = scrape_product(asin)
item["availability_status"] = product_result.get(
"availability_status", "Unknown"
)
Store the data
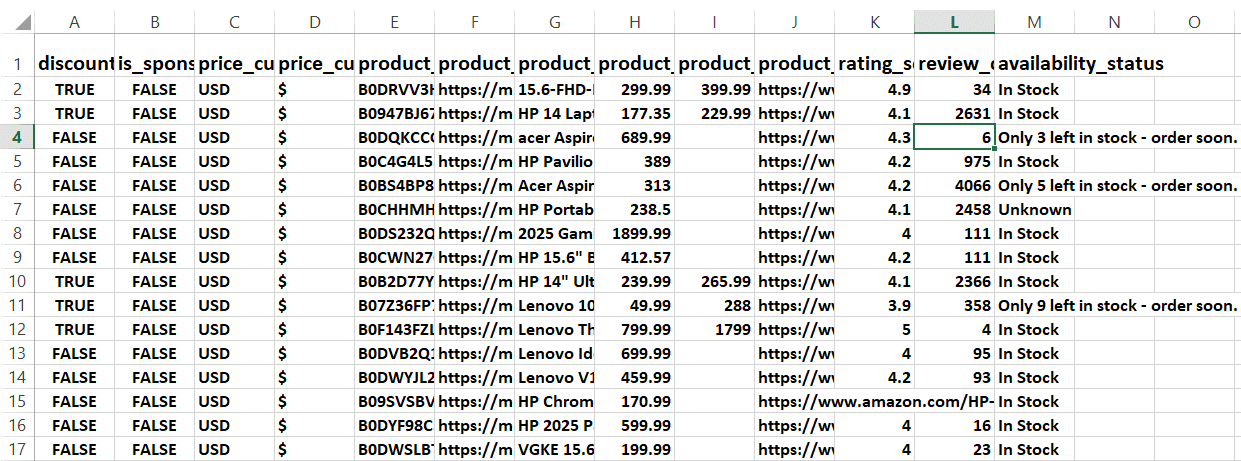
You can store the combined data in a CSV or dedicated database. The code below writes each product detail to a new CSV row and stores the file as products.csv:
# ...
# save to CSV
csv_filename = "products.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
writer.writeheader()
writer.writerows(data)
# pip install requests
import requests
import csv
params = {
"apikey": "YOUR_ZENROWS_API_KEY",
}
# API Endpoints
discovery_endpoint = "https://ecommerce.api.zenrows.com/v1/targets/amazon/discovery/"
product_endpoint = "https://ecommerce.api.zenrows.com/v1/targets/amazon/products/"
# search Term
search_term = "laptops"
# generic function to fetch data from the Scraper APIs
def scraper(endpoint, **kwargs):
url = f"{endpoint}{kwargs.get('suffix', '')}"
response = requests.get(url, params=params)
try:
return response.json()
except ValueError:
print(f"Failed to parse JSON from {url}")
return {}
# fetch product list
result = scraper(discovery_endpoint, suffix=search_term)
data = result.get("products_list", [])
# fetch product details for each item
for item in data:
ASIN = item.get("product_id")
if ASIN:
product_result = scraper(product_endpoint, suffix=ASIN)
item["availability_status"] = product_result.get(
"availability_status", "Unknown"
)
# save to CSV
csv_filename = "products.csv"
with open(csv_filename, mode="w", newline="", encoding="utf-8") as file:
writer = csv.DictWriter(file, fieldnames=data[0].keys())
writer.writeheader()
writer.writerows(data)
Conclusion
With only a few code changes, you’ve optimized your scraping script with the new Scraper APIs for a smoother and more efficient experience. No more time-consuming pagination challenges and parsing issues. Now, you can confidently collect data at scale while the ZenRows Scraper APIs handle the heavy lifting.