What Is MuleSoft?
MuleSoft is a no-code/low-code automation platform that connects and exchanges data between various applications and systems. One of its core components is the MuleSoft Anypoint platform, which enables users to integrate systems via an API-focused approach.Use Cases
Here are some use cases of MuleSoft-ZenRows integration.- Competitor monitoring: Schedule automated scraping of competitor websites to track pricing, product changes, or content updates.
- Sentiment analysis: Gather product reviews data from various sources with ZenRows and analyze their sentiment using LLM integration.
- Demand forecasting: Use cron jobs to scrape demand signals from retail and ecommerce sites with ZenRows. Calculate trends and historical moves with JavaScript via Anypoint’s Scripting module. Store time-series data in a database and forecast anticipated demand using LLM.
- Best deal recommendation: Collect product data from various platforms with ZenRows and use an LLM to analyze key points, such as price, demand history, reviews, and ratings, to recommend the best deal for your customers.
Initial Integration Steps via Anypoint Platform
The best way to integrate MuleSoft with ZenRows is via Anypoint. This guide assumes that you already have an Anypoint account with the Anypoint Studio downloaded and installed. We’ll create a scraping workflow that extracts data from an Amazon product page and stores it in a JSON file.Step 1: Create and deploy a ZenRows API Spec
- Log in to MuleSoft via the Anypoint platform.
-
Click the icon at the top left and go to Design Center.
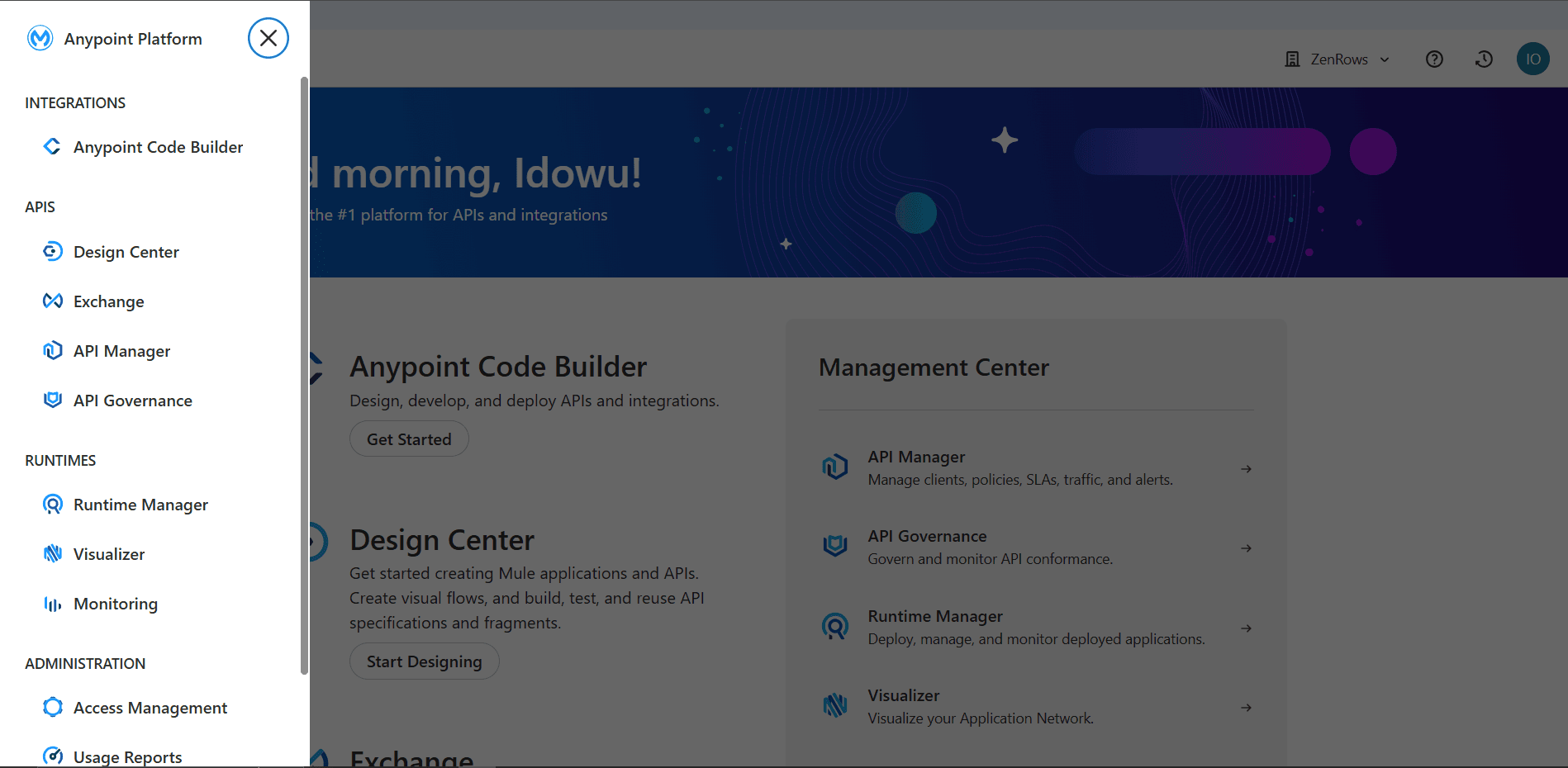
-
Click
Create +at the top-left and select New API Specification.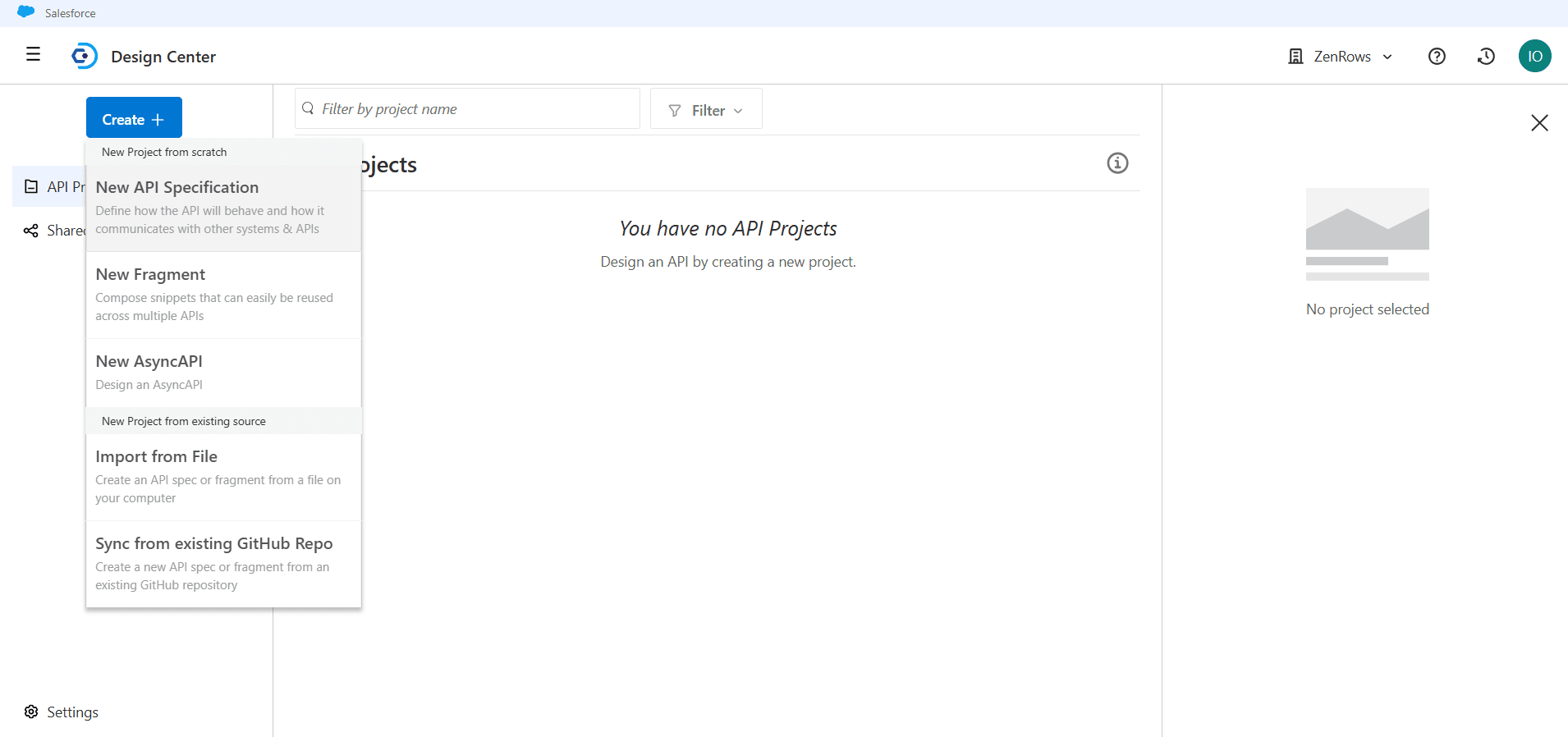
-
Give your project a name (e.g., ZenRows Universal Scraper). Then click
Create API.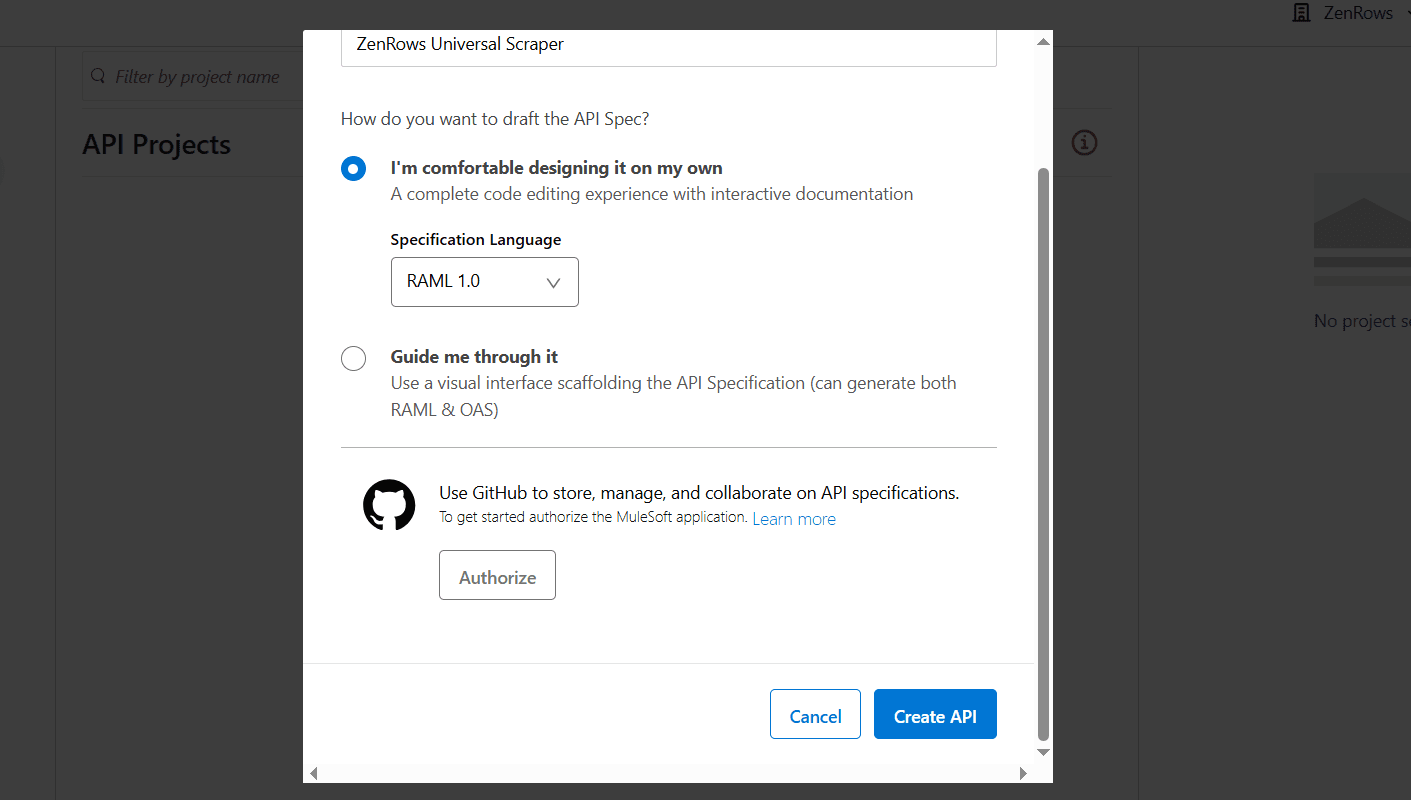
-
The Design Center creates a new
zenrows-universal-scraper.ramlfile. Remove the existing content in the RAML code box and paste the following ZenRows RAML configuration inside the code box. This configuration defines the required specs and parameters to use the ZenRows Universal Scraper API:RAML -
Click
Get. Then, clickPublishat the top right.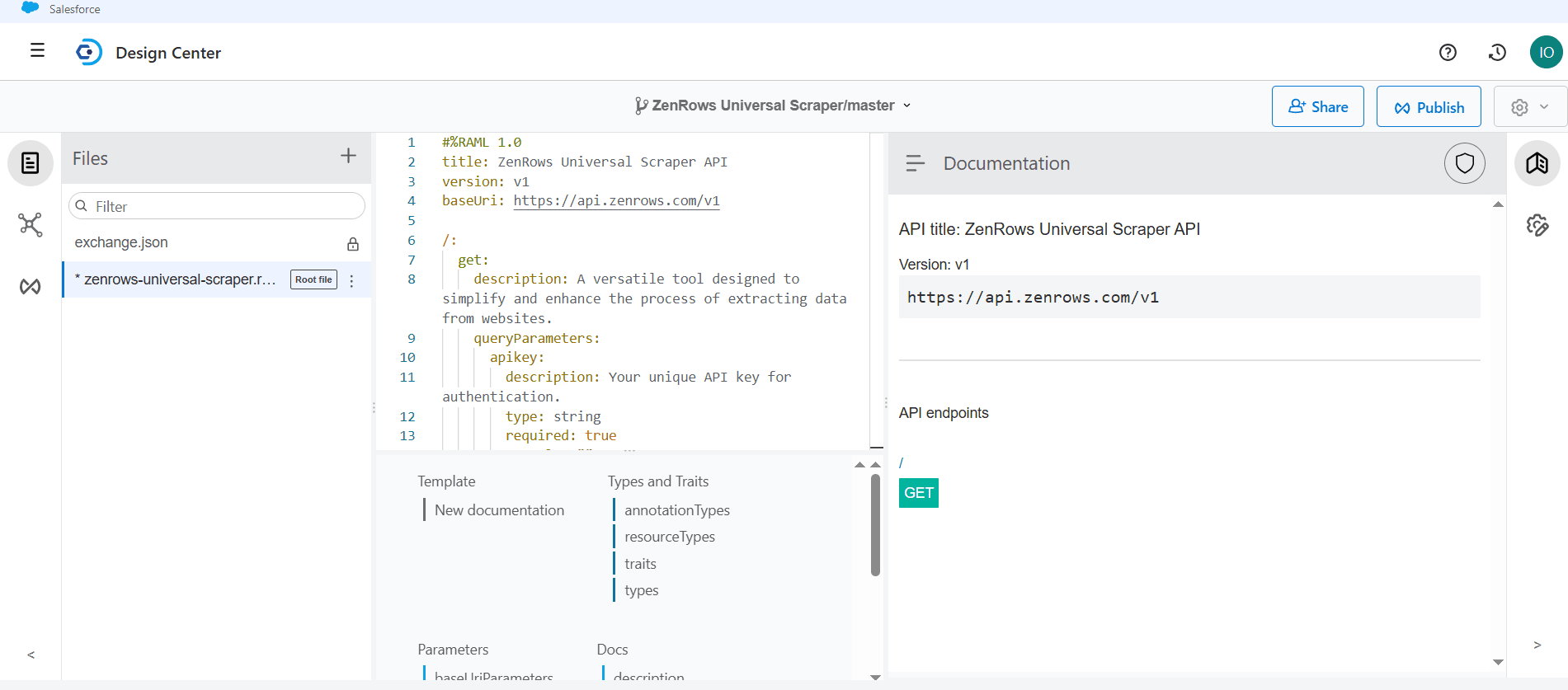
-
Keep the Asset Version and API Version as
1.0.0andv1, respectively. Under LifeCycle State, select Stable. -
Click
Publish to Exchange. -
Close the confirmation modal.
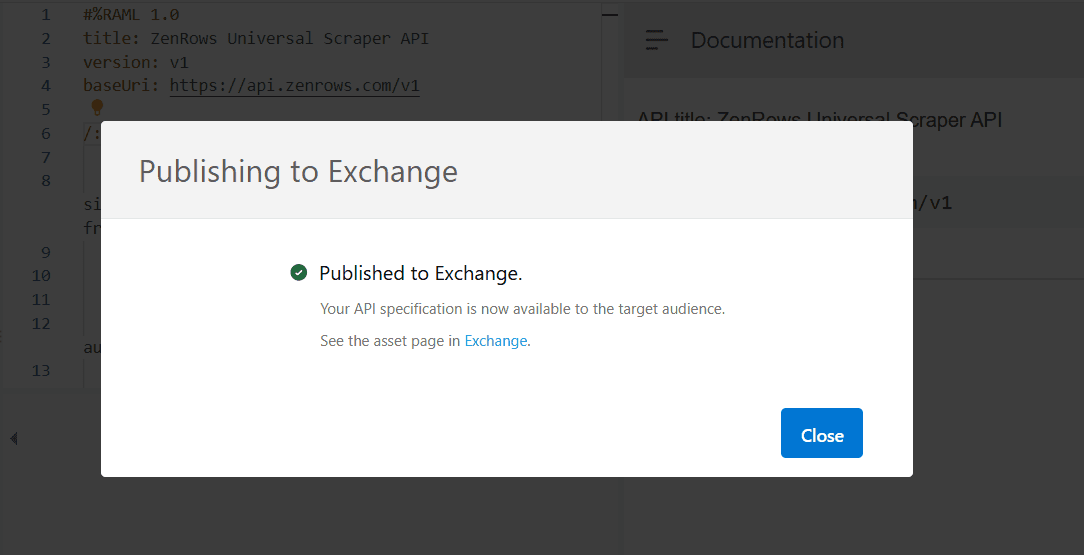
-
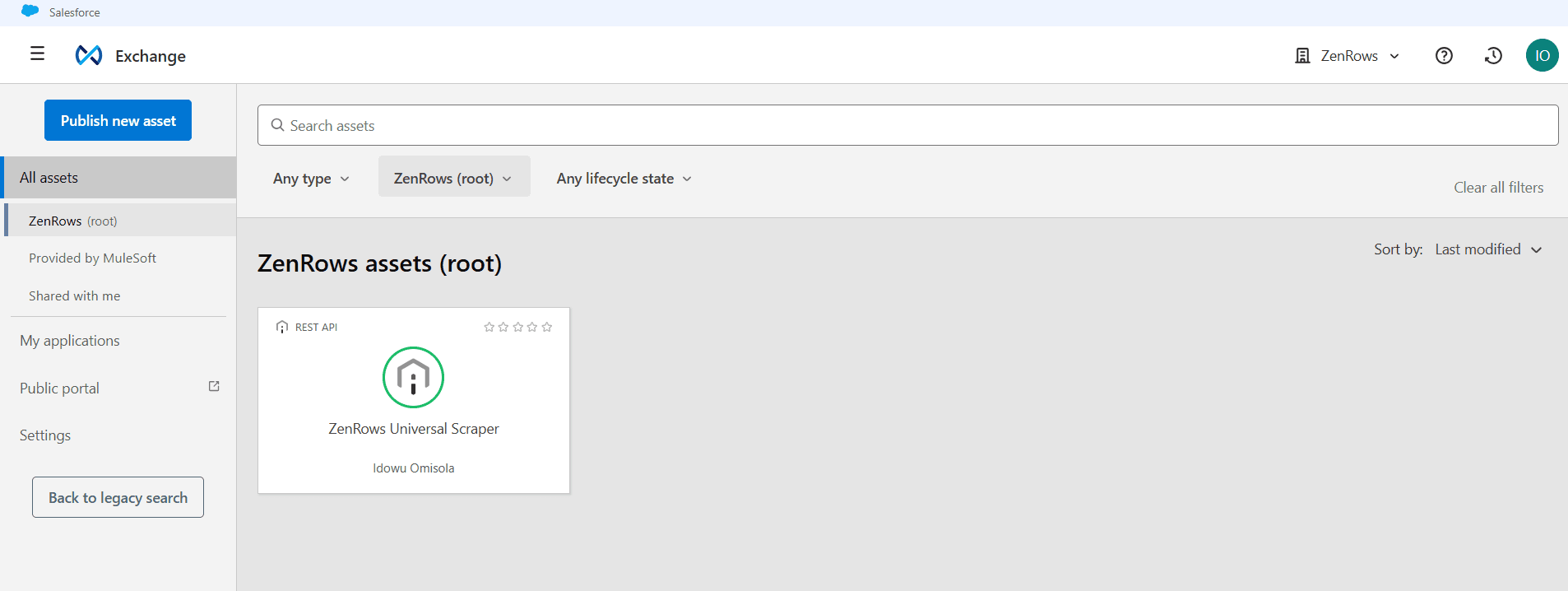
Click the menu icon at the top left and go to Exchange to view your published API spec in the Anypoint Exchange marketplace.
Step 2: Import the ZenRows API Spec into Anypoint Studio
- Launch the Anypoint Studio on your machine.
-
Click
Fileat the top left and go to New. Then, select Mule Project.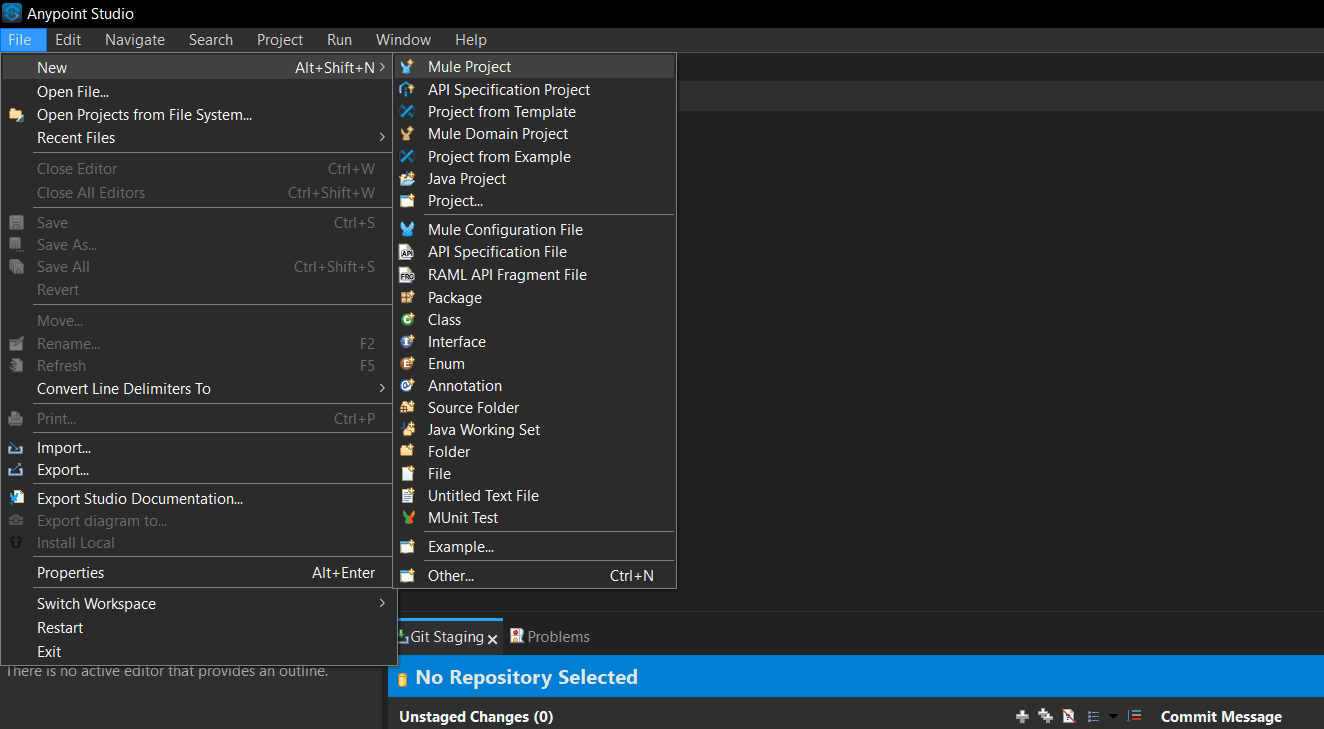
-
Give your project a name (e.g., Scraper) and click
Finish.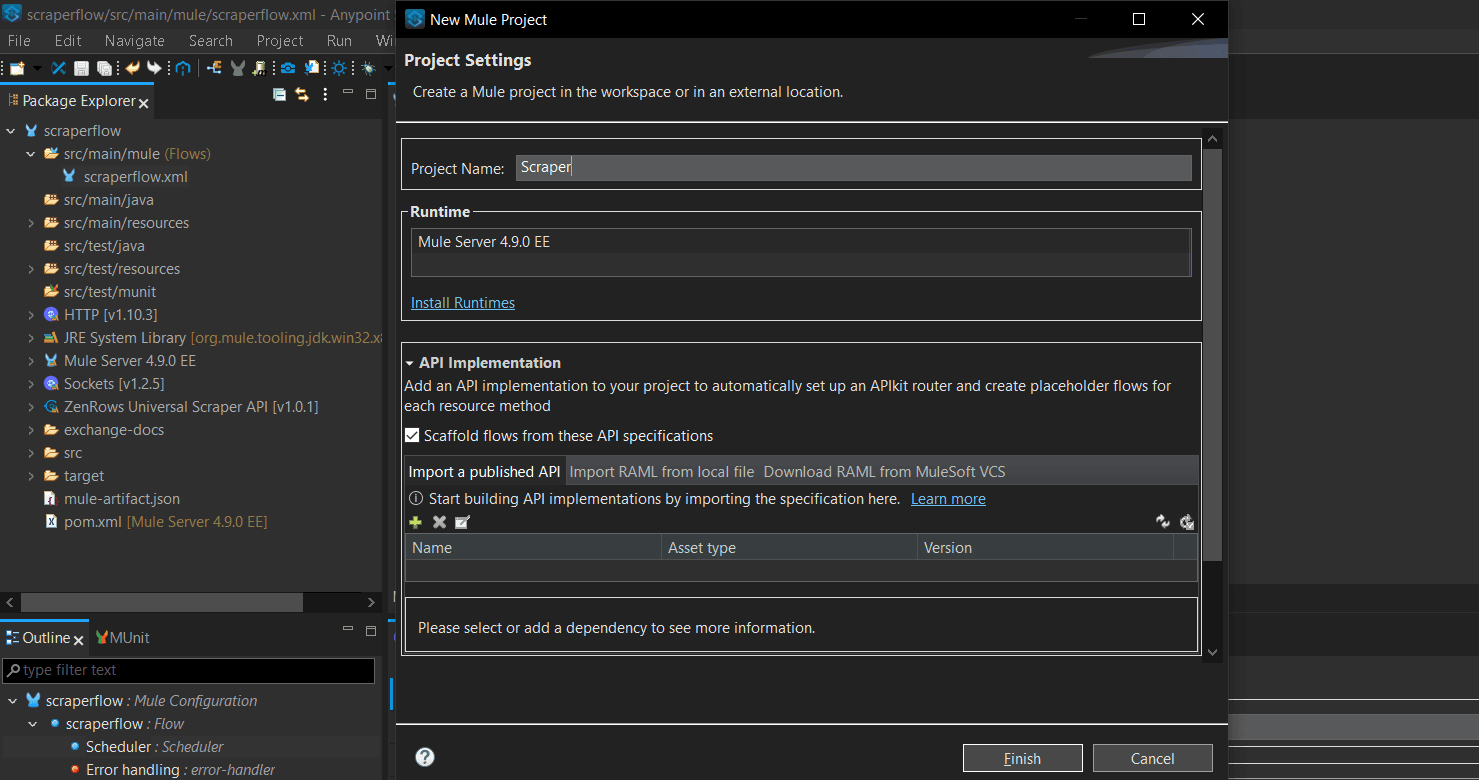
-
Double-click the
<project.xml>(scraperflow.xml) file on the left sidebar to load the flow canvas. -
From the Mule Palette on the right side of the canvas, click
Search in Exchange.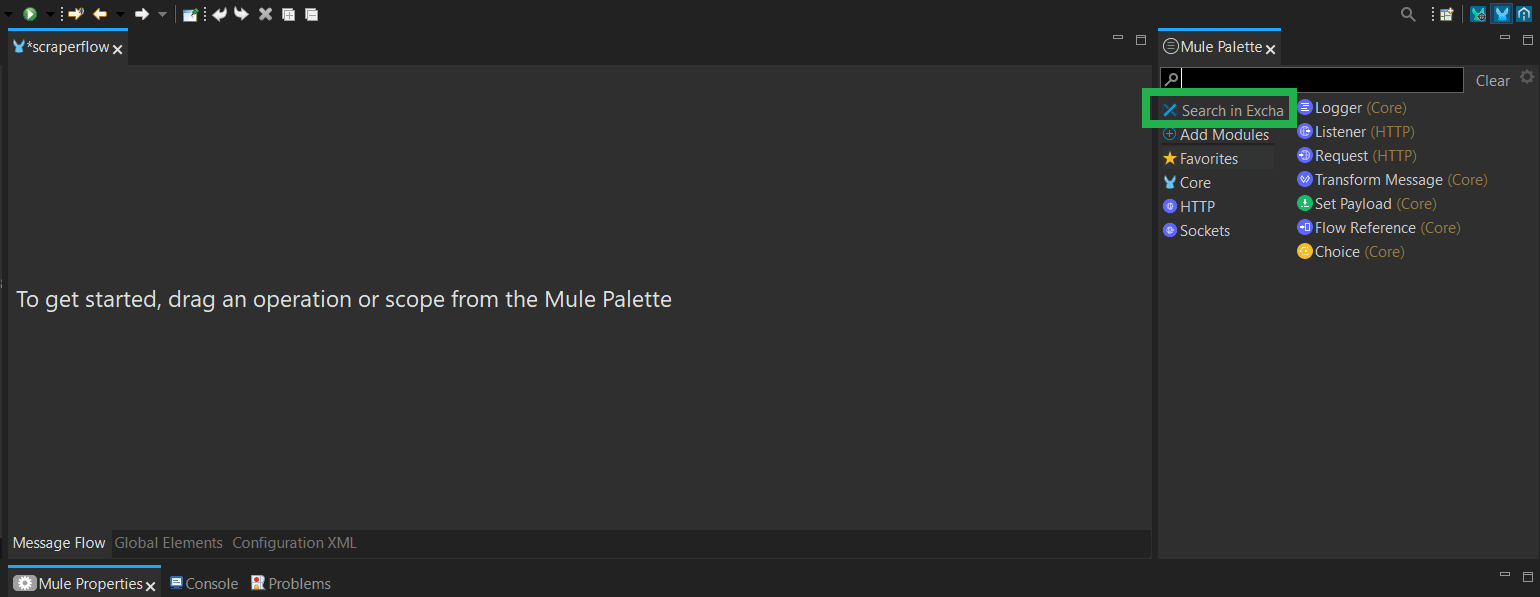
-
Click
Add Accountand authenticate Anypoint Studio with your Anypoint account if you haven’t done so already. - Search for ZenRows in the search bar and select the ZenRows Universal Scraper API spec from the result table.
-
Click
Addto load the API spec into the Anypoint Studio Mule Palette. -
Click
Finish.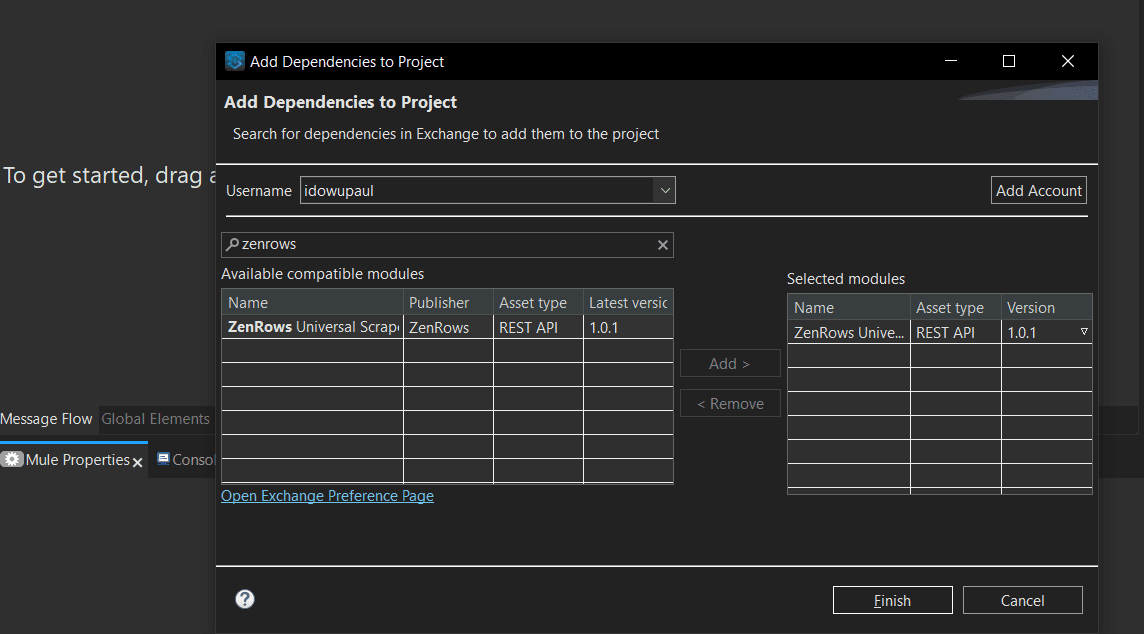
-
To test the import, search for ZenRows via the Mule Palette search bar. The ZenRows Universal Scraper spec now appears in the Mule Palette.
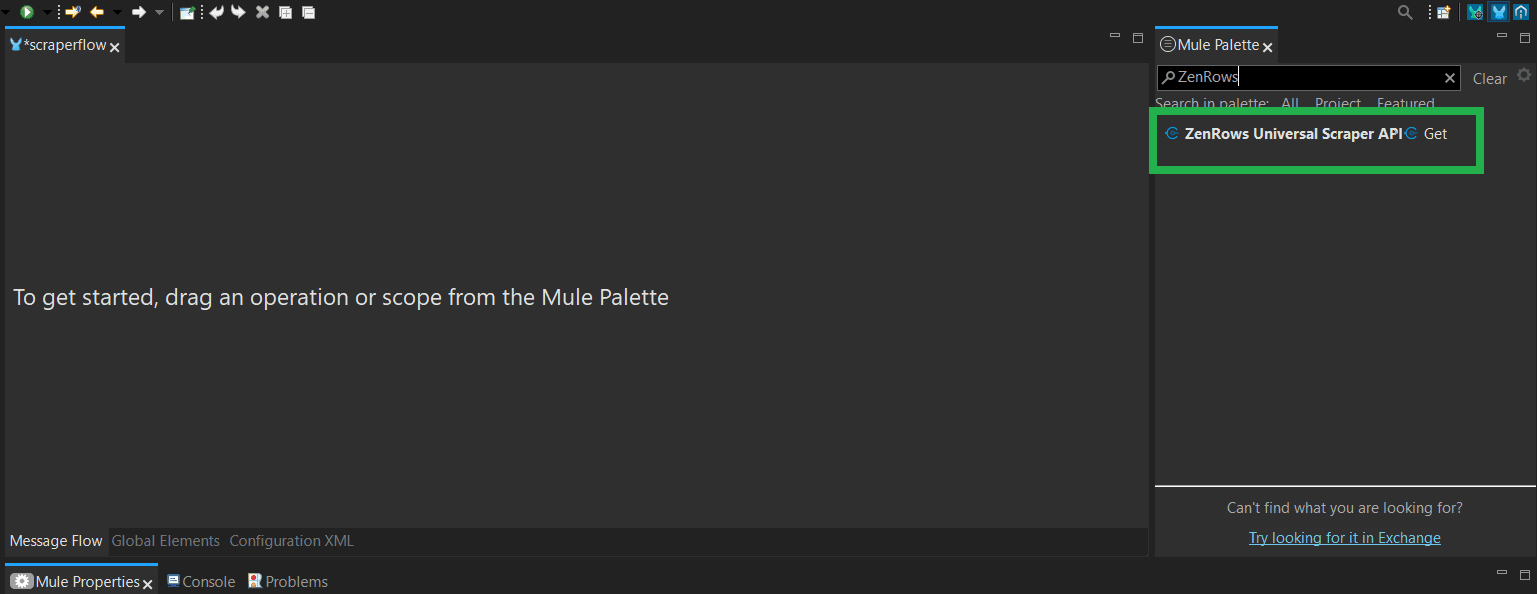
Step 3: Create the scraping workflow in Anypoint Studio
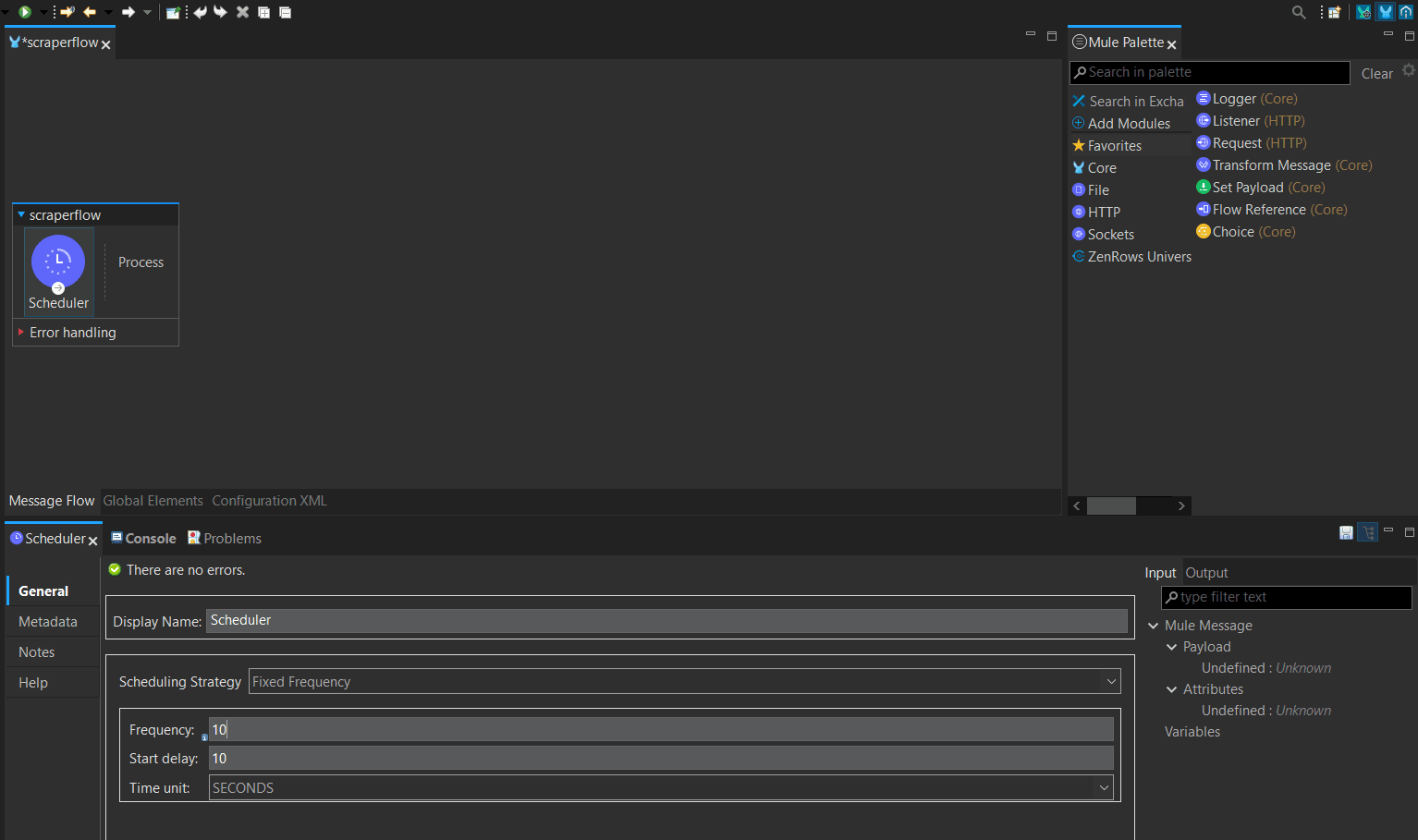
- From the Mule Palette, search for Scheduler and drag it into the canvas. Rename your scheduler as you desire.
-
From the Scheduling Strategy dropdown, choose between Frequency or Cron. We’ve chosen Frequency in this case and scheduled the flow to run the request within 10 seconds using a 10-second delay.
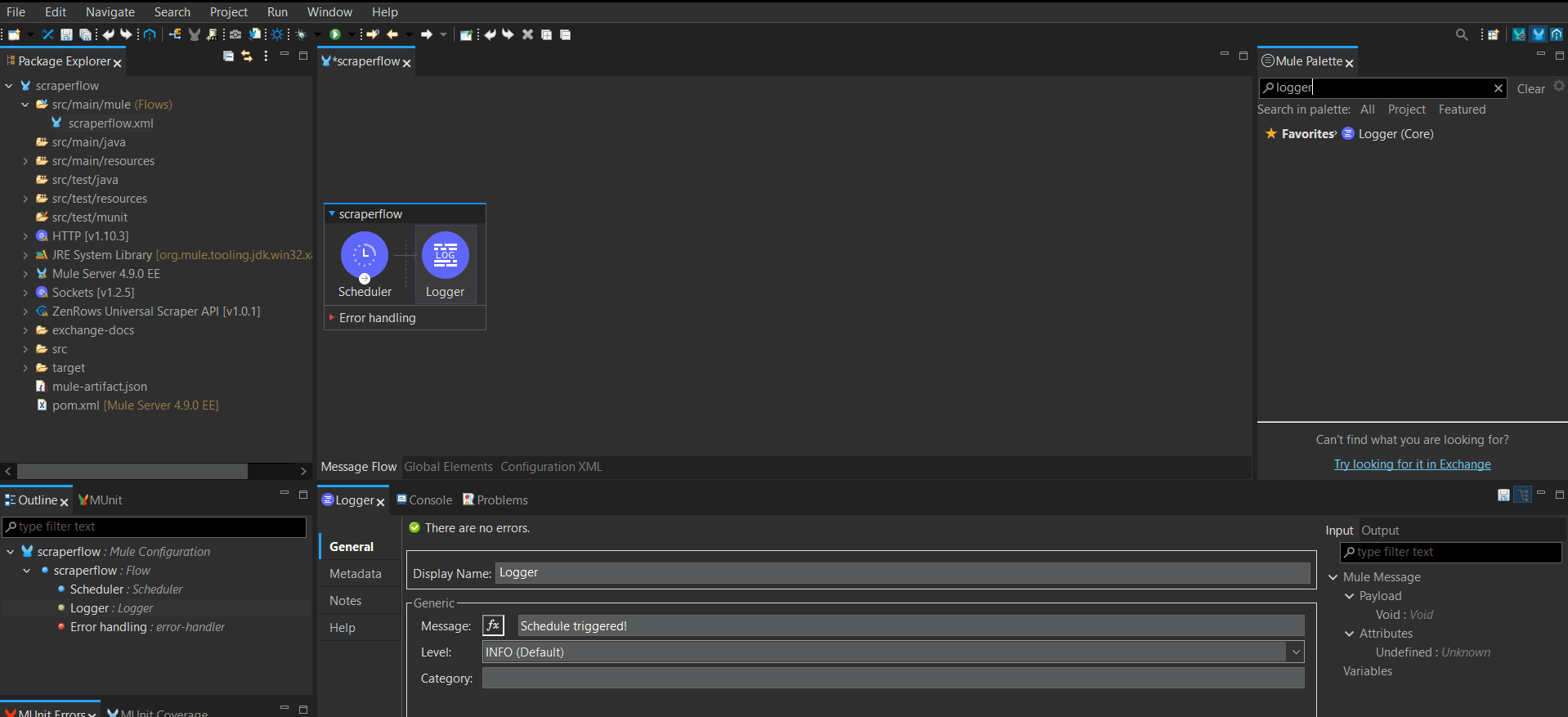
- Search for Logger and drag it into the Process tab inside the Scraperflow. We’ll use this to log the beginning of automation.
-
In the Message box, type a trigger alert message (e.g., Schedule triggered!).
- Search for ZenRows in the Mule Palette. Then, drag the ZenRows Universal Scraper API spec into the workflow.
- Click the Connector Configuration dropdown and select Create a new configuration.
- Rename the ZenRows flow as you desire (e.g., Product Scraper Flow).
-
Click the
+icon next to Connector Configuration and click okay to set it as ZenRows.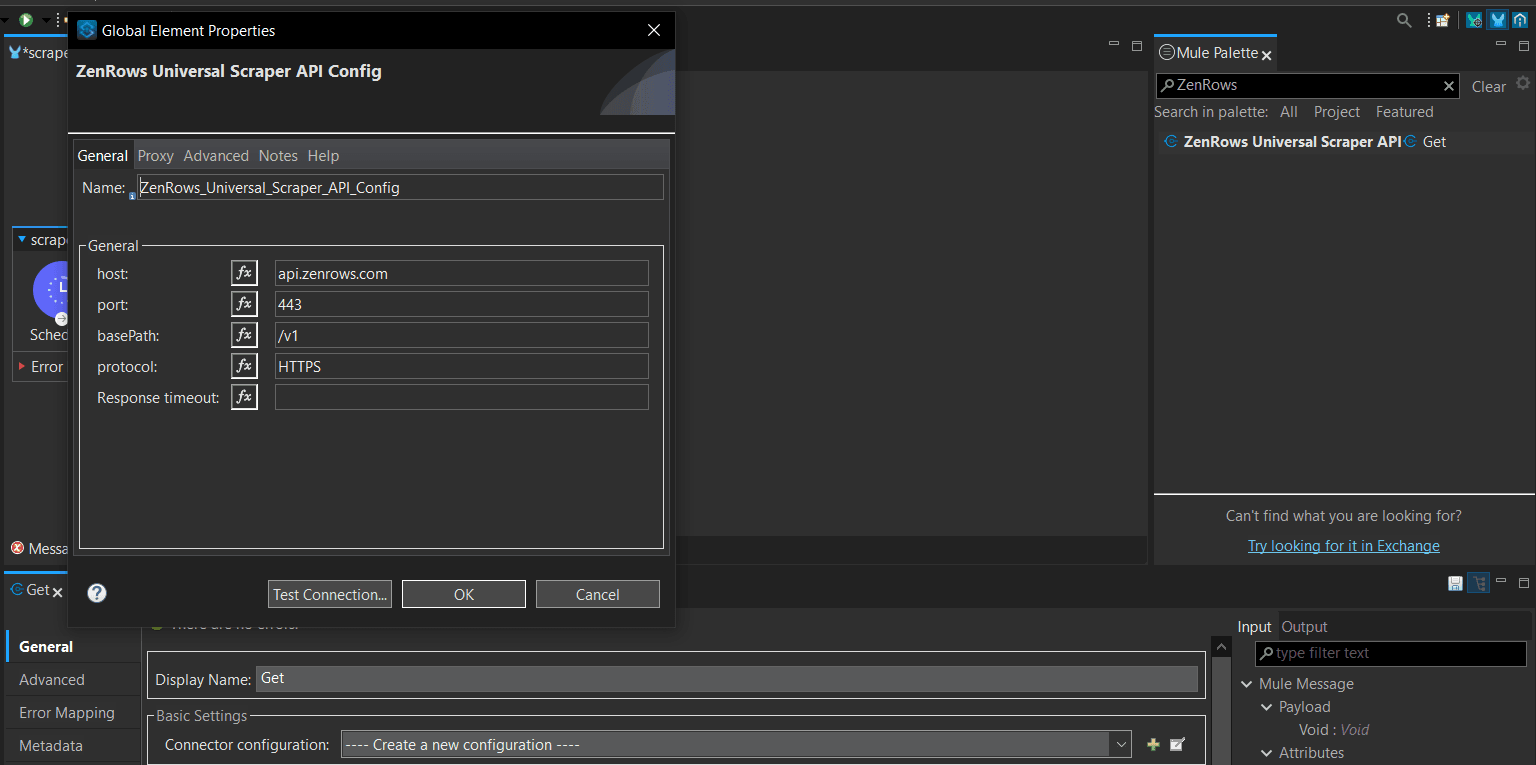
-
Set the necessary parameters. We’ve used the following in this guide:
- ZenRows API key.
- Target URL
- Js_render = true
- Premium_proxy = true
- Proxy_country = us
- css_extractor:
JSON
-
Press
Ctrl+Son your keyboard to save the current flow.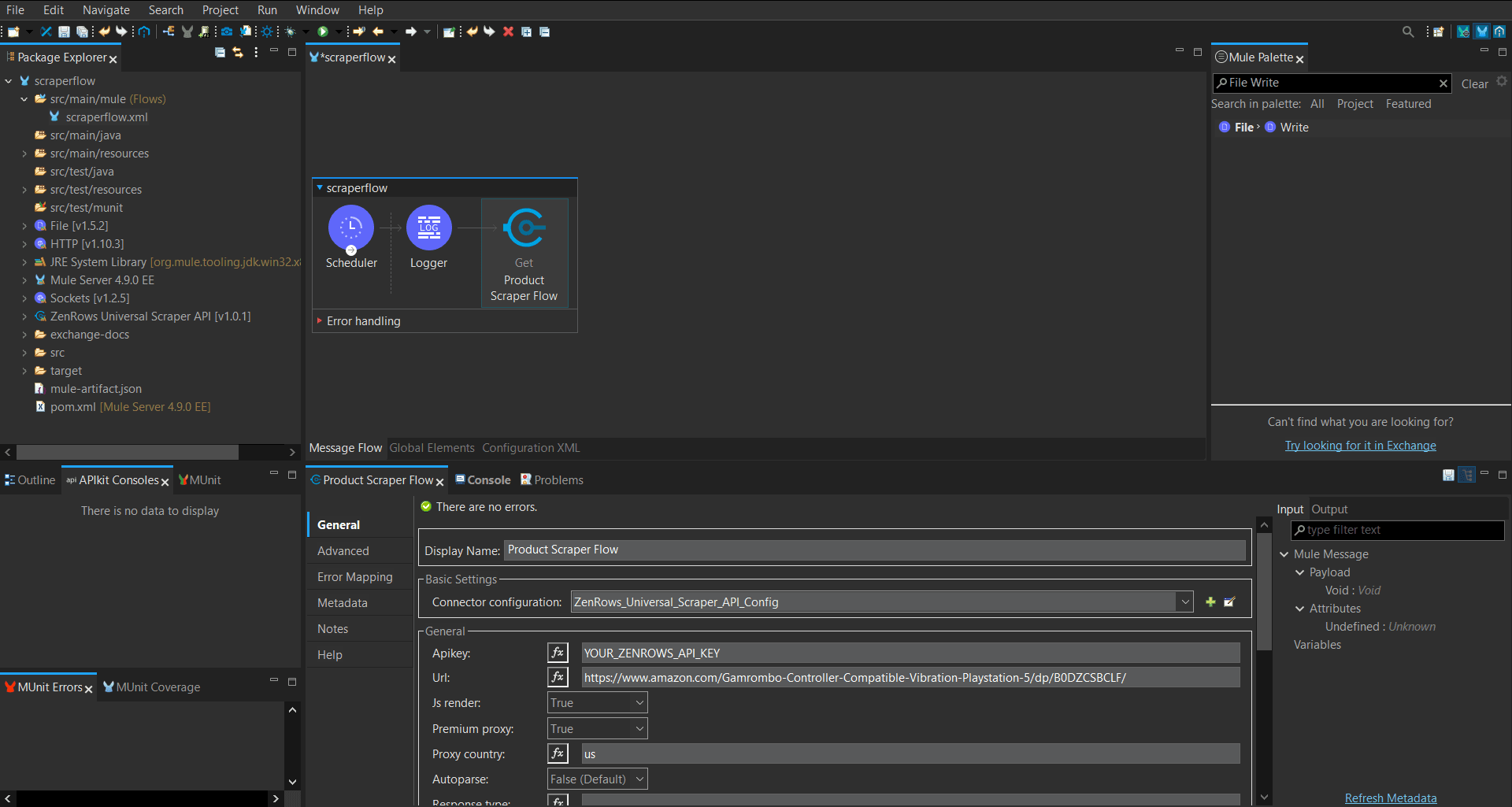
- Again, search and drag a Logger flow into the workflow to output the scraping result.
- Rename the new logger (e.g., Data Logger)
-
In the Logger’s Message, click
fxand type#[payload.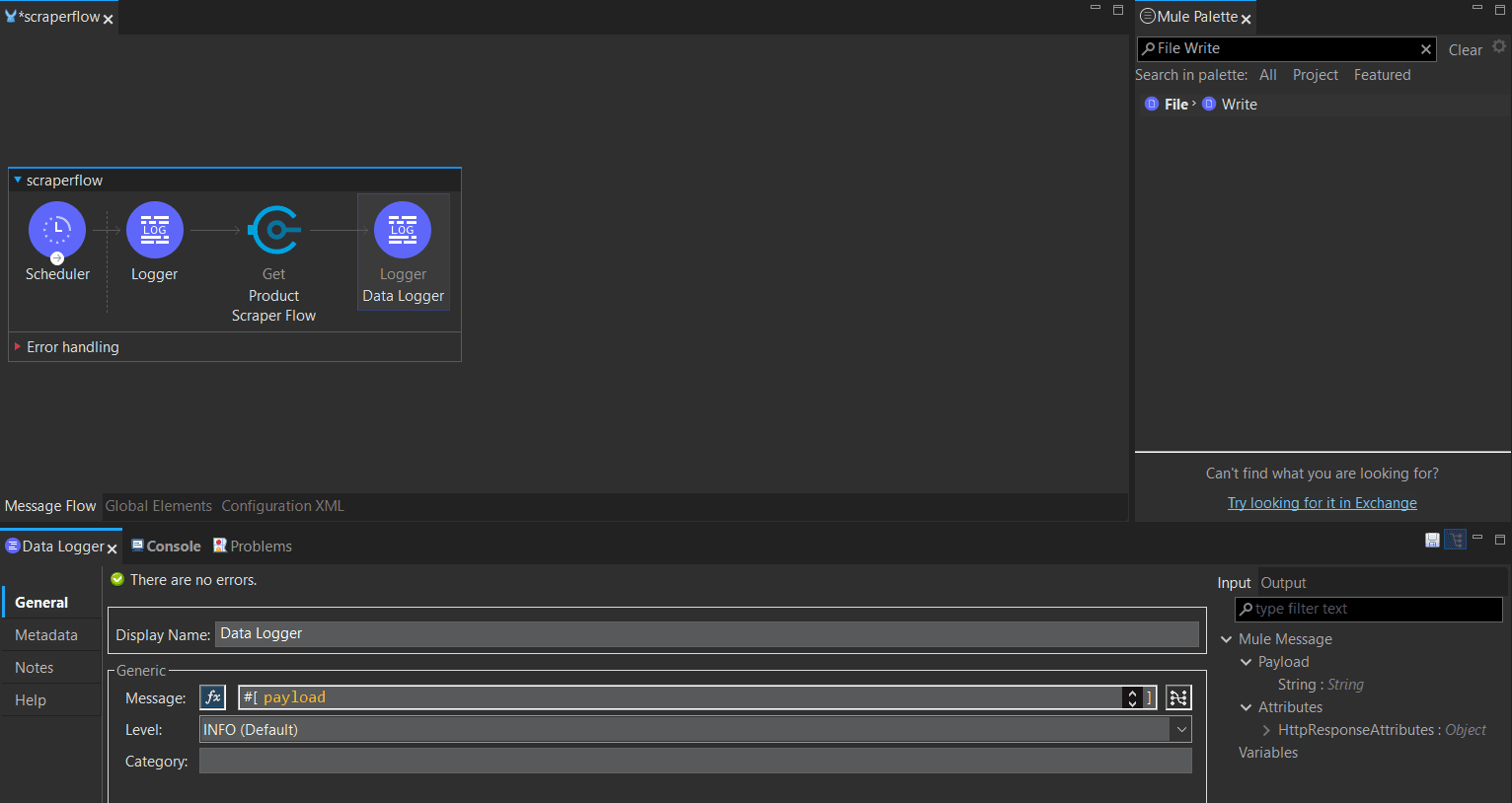
Step 4: Save the data
- Search for File Write in the Mule Palette and drag it into your workflow.
- Rename the Writer (e.g., JSON Writer).
-
Paste the destination folder path in the Path field (e.g.,
D:/Anypoint-result/result.json). Keep the Content field as payload and the Write Mode as OVERWRITE. -
Press Ctrl+S to save the changes.
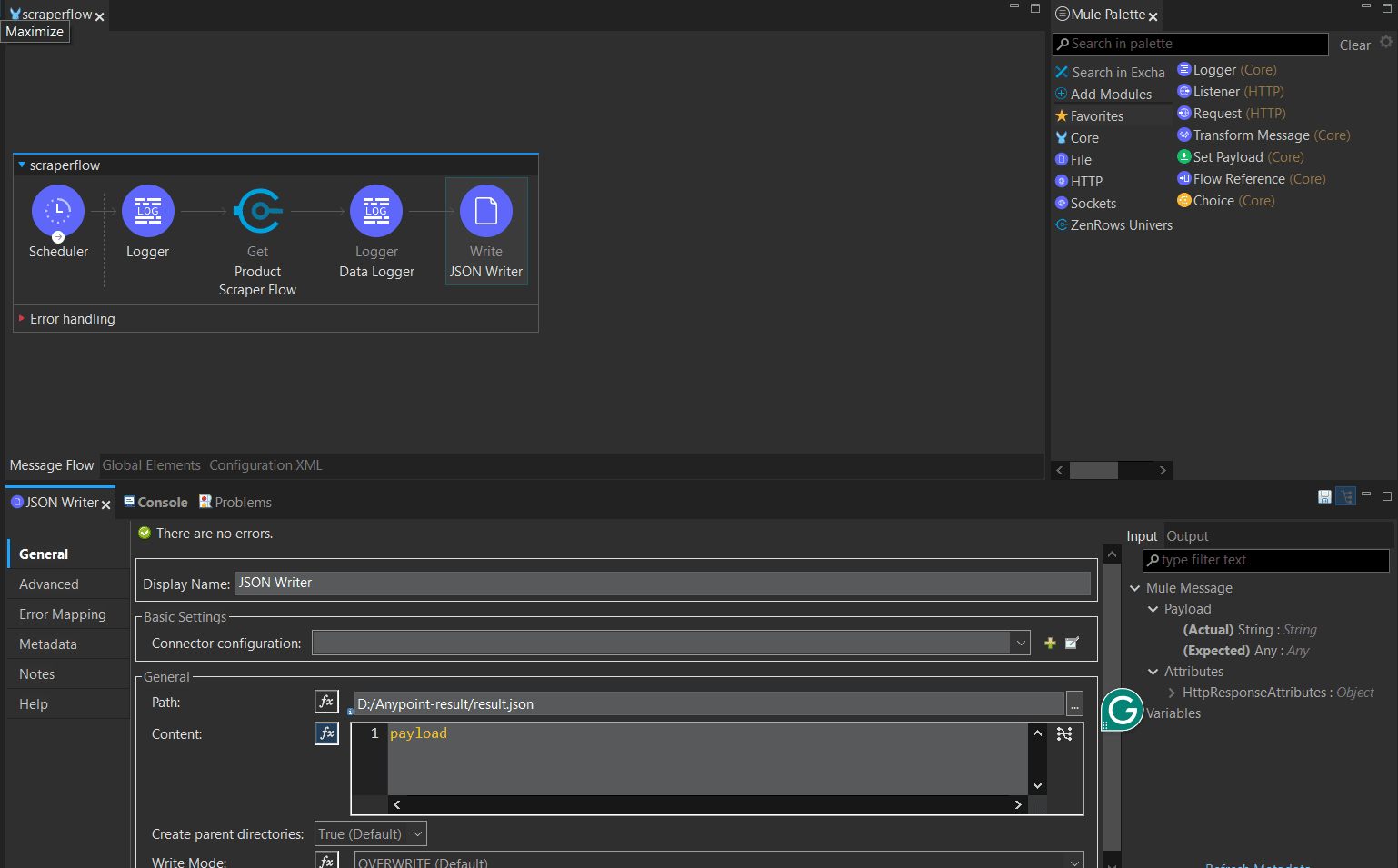
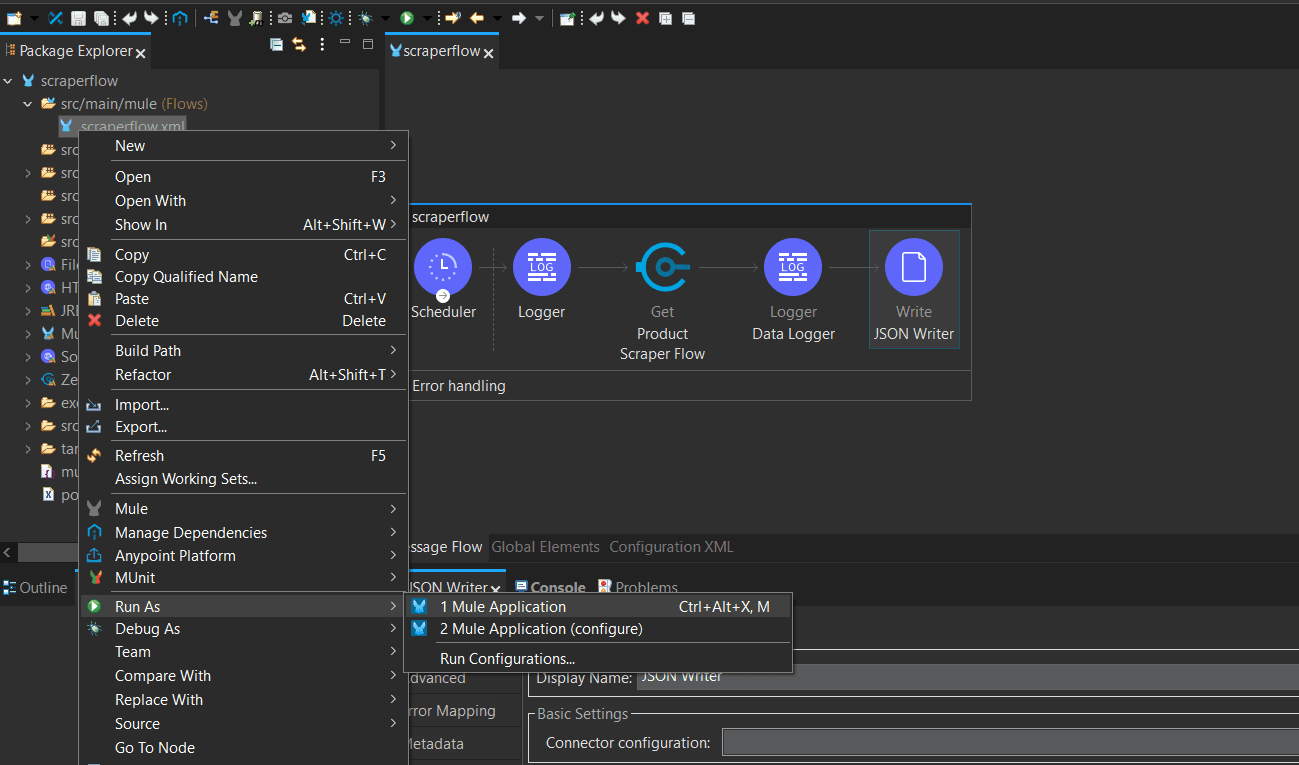
Step 5: Run the flow
To run the flow, right-clickscraperflow.xml, click Run As > Mule Application.
 Check your JSON storage directory and open the created JSON file to see the scraped data.
Here’s a sample JSON result:
Check your JSON storage directory and open the created JSON file to see the scraped data.
Here’s a sample JSON result:
result.json
Troubleshooting
Error 429 (Too Many Requests)
- Solution: Increase the Scheduler’s frequency and delay to space out the requests and prevent multiple requests from running within a short time frame.
Build failed during Anypoint Studio compilation
- Solution 1: Check for errors in each flow and fix them individually.
- Solution 2: Ensure you enter the correct ZenRows parameters. The
js_renderandpremium_proxyparameters should be set totrueto increase the success rate. - Solution 3: Verify that your API key is entered correctly.
Incomplete or empty data
- Solution 1: Ensure that you enter the correct CSS selectors.
- Solution 2: Validate that the CSS extractor array is formatted correctly.
- Solution 3: If using autoparse, ensure that ZenRows supports the target page. Check the ZenRows Data Collector Marketplace to view the supported websites.
File write access denied:
- Solution 1: If storing data locally, give the current Anypoint Studio workplace access to the storage location.
- Solution 2: Ensure that you append the file name to the file path specified in the Anypoint Studio Writer flow. For example,
D:/Anypoint-resultis wrong. The correct file path format should beD:/Anypoint-result/result.json.
Frequently Asked Questions (FAQ)
Does MuleSoft and ZenRows integration incur additional costs?
Does MuleSoft and ZenRows integration incur additional costs?
ZenRows doesn’t charge you extra for making scraping requests via Anypoint. However, while Anypoint comes with a 30-day free trial, it requires an upfront financial commitment, which limits your ability to use the scraping workflow.
Does MuleSoft support writing scraped data to a CSV file or a remote database?
Does MuleSoft support writing scraped data to a CSV file or a remote database?
Yes, you can save data locally to a CSV file using Anypoint’s File Write module. MuleSoft’s Anypoint also supports remote database connection using the JDBC (Java Database Connectivity) driver.
Is ZenRows integration built into MuleSoft's Anypoint platform?
Is ZenRows integration built into MuleSoft's Anypoint platform?
No, but integrating ZenRows with MuleSoft is straightforward. You only need to paste the RAML file containing the required ZenRows Universal Scraper API specifications into the Anypoint Platform and publish it to the Exchange. You can then interact with ZenRows visually in your workflow via the published API specification.
Does MuleSoft's Anypoint support AI integration?
Does MuleSoft's Anypoint support AI integration?
Although Anypoint doesn’t have built-in support for LLM tools, you can load your desired model using Anypoint’s HTTP request flow. This involves authorizing the LLM via the Bearer Authorization header and returning its response using a Logger flow or directly writing it into a file.